Abstract
Transformer模型架构在自然语言处理、计算机视觉、强化学习等领域表现出了强大的能力,已经成为当前深度学习很多模型的核心,当前发展迅速的大模型更加凸显出这一点。由于Transformer较高的复杂度,限制了其在很多场景中的应用。因此,为了提高模型的高效性,针对Transformer的改进层出不穷。本文从模型算法的角度出发,关注于模型推理的场景,从不同层次梳理当前提高模型效率的方法,包括设计复杂度更低的注意力机制、提出更加高效的网络设计、进行模型压缩和优化的方法,并针对每一种方法进一步做了分类和总结,并选取具有代表性的方法进行说明。本文最后探讨了Transformer未来可能的发展方向。
1. Introduction
近年来,深度学习发展迅速,尤其是以Transformer为核心的结构,构成了当前深度学习架构的核心,在计算机视觉、自然语言处理等领域,SOTA的模型均以Transformer架构为核心,而且当前诸如ChatGPT等大模型,核心同样是基于RLHF的Transformer,显示出了Transformer强大的能力。
但是,受限于Transformer相对于序列长度平方的计算复杂度,在图片、视频等需要长序列的场景下,相对于传统的CNN架构,Transformer仍不够有效,无法得到有效的应用。Transformer的平方复杂度来源于注意力机制,因此,许多研究关注于改进注意力机制,降低注意力机制的复杂度,提出新的注意力机制。除此之外,不同的Transformer架构被提出,这些架构在Vanilla Transformer架构上做出改进来提高计算和访存效率,这可以归结为efficient attention或efficient Transformer网络架构的设计。
除此之外,为了进一步降低Transformer模型的复杂度,提高模型的推理速度,efficient Transformer的网络架构还可以使用一些模型压缩的方法,比如剪枝、量化、蒸馏、神经架构搜索(NAS)等,这些方法可以在基本保持模型效果的同时,降低模型复杂度,减小模型大小,进一步加速模型的推理。
需要说明的是,efficiency是一个比较宽泛的用词,包括data-efficiency, model-efficiency(efficient architecture),training-efficiency,inference-efficiency。其中data-efficiency一般指充分利用、挖掘数据,从小规模数据中进行学习;model-efficiency侧重于降低模型的复杂度或是参数量;training-efficiency指使用更少的资源(或提高资源利用效率)、使用更少的时间来进行训练;inference-efficiency通常也被成为模型推理加速,它针对训练好的模型,尽可能提高模型的推理速度、吞吐量等。本综述中只涉及到model-efficiency,并介绍一些针对Transformer的模型压缩方法。
2. Model Efficiency
Model efficiency主要侧重于提出新的架构,或者改善现有架构,从而降低模型复杂度或参数量。不同于训练场景只关注于模型的参数量,在推理场景中,模型在访存、计算等方面同样需要高效,2.1节说明了在推理场景中模型所关注的几种不同的efficiency。为了能够量化的来比较模型在推理时的efficiency,2.2节总结了一些评估模型推理性能的指标。
2.1 Kinds of Efficiency
模型的高效是一个相对的概念,但是有几个发展方向是确定的,比如高效的模型一般具有一下几个特征:模型中存在较多的计算密集型算子而非访存密集型算子(有助于充分发挥硬件性能),模型计算复杂度尽量低(可以应用于更加广泛的场景),模型参数量尽量少(可以减少存储空间和内存的占用),受限于模型的结构、应用的场景,在应用中需要先对这几个方向进行分析,然后才能够做进一步的分析和优化。
2.1.1 Memory Efficiency
访问内存的开销是影响模型推理速度的一个关键因素。Transformer中许多操作,比如频繁的reshape,element-wise相加,归一化等操作,这些操作或算子是访存密集型的,即大部分时间花费在访存上,而计算耗时占比很小,此时模型推理速度主要受到内存带宽限制。减少模型推理过程在访存上的时间开销,就是提高memory efficiency。
2.1.2. Computation Efficiency
模型的computation efficiency往往指的是模型的算法复杂度低。特别的,针对Transformer而言,当序列长度序列较小时,此时模型的计算开销主要集中在FFN模块,计算复杂度近似地线性于序列长度。但是在很多使用Transformer的场景中,比如图片、视频等场景中,输入序列长度较大。此时,模型的计算开销会集中于自注意力层,产生相对于序列长度平方的复杂度,限制了Transformer在很多场景中的应用。
Paper: Attention is all you need 中FFN与Attention复杂度对比
2.1.3 Parameter Efficiency
Parameter Efficiency主要指的是模型的轻量化和较少的参数量。使用参数量较少的模型,可以减少模型在磁盘上存储的空间和模型加载后内存的占用。需要注意的是,随着大模型的发展,受限于大模型训练的成本,大模型的微调技术PEFT(Parameter-efficient fine-tuning)发展迅速。PEFT旨在最小化微调参数的数量和计算复杂度,以减少大模型微调的成本,来提高模型在新任务上的性能。这里所说的Parameter Efficiency更加类似于模型轻量化的概念。
2.2 Metrics
设计神经网络架构的主要考虑因素之一就是效果和成本的权衡。一般情况下,一个模型的参数量越多,计算量越大,模型的容量越大,该模型的效果就越好。但是,不同模型在不同硬件平台上的推理效果往往无法直接比较。因此,在比较模型推理性能时,经常会使用一些指标,从不同角度对模型的推理性能进行比较。
2.2.1 计算量
计算量是评价模型efficiency最常用的指标,包括很多文献进行对比时,常常会将计算量和参数量作为最重要的比较依据。计算量是模型所需的计算次数,模型的整体计算量等于模型中每个算子的计算量之和。衡量计算量主要有两个指标:
FLOPs(Floating Point Operations,浮点计算次数):计算量一般用OPs(Operations,计算次数)来表示,由于最常用的格式为float32,因此也常被写作为FLOPs。
MACs(Multiply-Accumulate Operations,乘加累计操作数):1个MACs包括一个乘法操作与一个加法操作,大约相当于2FLOPs。在很多硬件上,Multiply-Accumulate可以使用单独一个指令完成,而且很多对tensor的操作也是Multiply-Accumulate操作。FLOPs通常用于模型的理论上计算量的分析,MACs更加贴近真实的计算量。
2.2.2 参数量
参数量是模型中参数的总和,直接反应了模型在磁盘中存储的大小。虽然参数量并不直接影响推理性能,但是参数量一方面会影响内存占用,另一方面会影响程序初始化时间。而且,在某些场景下,参数量是很重要的指标。比如在嵌入式或移动端场景下,磁盘空间极其有限,此时往往会对模型的参数量有比较严格的限制。在这种情况下,除了在设计时减少参数量,还可以通过压缩模型权重的方式进一步降低打包后模型的大小,但是这样会带来解压缩开销,会在一定程度上增加程序初始化的时间。
2.2.3 访存量
访存量往往是最容易被忽略的指标,但它对推理性能有着极大的影响。访存量是指模型推理时所需访问内存的数据量,反应了模型对存储带宽的要求。访存量有时也称作MAC(Memory Access Cost)或者MOPs(Memory Operations),一般用Bytes(或KM/MB/GB)来表示,即模型需要读取/写入多少Bytes的内存数据。和计算量一样,模型整体访存量等于模型各个算子的访存量之和。
2.2.4 运行速度
运行速度是衡量模型efficiency最有效的指标,但是需要基于相同的硬件平台进行对比,而且,即使使用相同的硬件平台,使用不同的软件环境、使用流水线的效率等因素也对最终的推理速度有极大的影响,所以往往在实践中难以直接进行比较。运行速度主要有两种形式进行反应:
- 吞吐量(Throughput):在单位时间内处理的样本个数,相当于可以并行处理的任务量,充分利用流水线可以极大提高模型推理的吞吐量。
- 延迟(Latency):通常指单个样本或单个batch处理完成的时间,相当于串行处理一个任务所需要的时间。相对于吞吐量,流水线无法减少延迟。因此,对于需要实时推理的模型而言,需要考虑延迟而非提高吞吐量。
[Paper: THE EFFICIENCY MISNOMER]
需要注意的是,使用单个指标对模型进行评估往往会导致不全面的结论,甚至评价指标无法真实地比较模型在硬件上的推理速度。比如在下图中,相较于其他网络,在保持类似精确度的情况下,EfficientNet具有相对较小的计算量(GFLOPs)和参数量(Million Parameters),但是模型的推理速度并没有相对于其他模型很明显的提升,甚至有时其他模型推理速度更快一些。虽然如此,但是固定某些指标进行比较,仍是一个相对公平的方法。而且通过分析模型的推理瓶颈,可以针对性的提升模型的某些指标,从而加速推理。
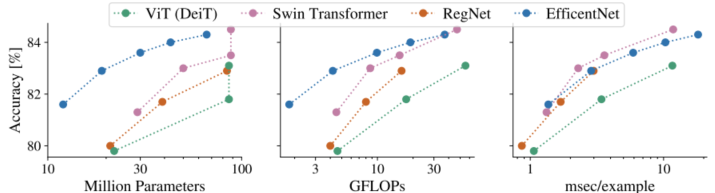
Paper: THE EFFICIENCY MISNOMER Figure5
2.3 Find the Bottleneck
不同的模型具有不同的特征,即使同一个模型的不同部分也有不同的特征,比如某些部分是计算密集性的,有些部分是访存密集型的,这里选取Bert和GPT-2两个典型的模型进行分析。
为了综合衡量计算密集型与访存密集型,通常使用算数强度(arithmetic intensity,也称计算密度,计算强度,计算访存比等)来表示。算数强度表示从内存加载的每个字节可以进行的浮点运算的数量,反映了程序相对于访存而言计算的密集程度,可以通过计算量FLOPs除以访存量来计算得到。RoofLine模型是基于算数强度,来评估程序在硬件上能达到性能上界的模型,即给定一个硬件资源的限制(算力、内存带宽),模型在该硬件上可以达到的最大计算速度。
当模型的计算密度较小时,访存相对较多,计算相对较少,模型性能主要受到内存带宽限制,此时模型是访存密集型的。反之如果模型的计算密度较大,访存相对较少,计算相对较多,模型性能主要受到硬件算力的限制,此时模型是计算密集型的。一般而言,模型的计算密度越大,越有可能提升硬件的计算效率,充分发挥硬件性能。对于访存密集型算子,推理时间跟访存量呈线性关系,而对于计算密集型算子,推理时间跟计算量呈线性关系。
[Paper: Roofline: An Insightful Visual Performance Model for Floating-Point Programs and Multicore Architectures]
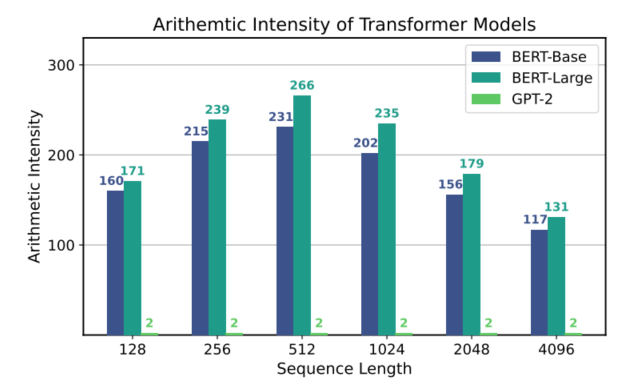
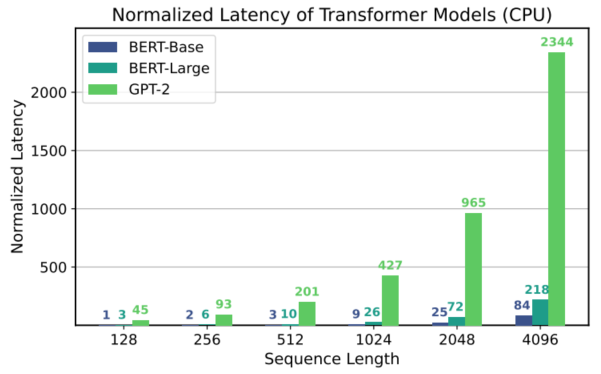
BERT是Encoder-only的模型,而GPT-2是Decoder-only的模型,如图a所示,这个区别导致两类模型的计算密度差异很大,而两种不同大小的BERT模型的计算密度差异反而不是很大。究其原因,是由于Decoder模型中,每次都是逐个token输入并解码,导致实际矩阵乘法退化为矩阵与向量的乘法,数据重用有限,使其更容易受到内存带宽的限制。因此,如图b所示,当使用高算力的硬件进行推理性能测试时,以BERT-Base的推理时间为基准,尽管相对于BERT-Base,GPT-2具有更少的计算量,但是由于访存量的激增,导致计算密度变低,最终在实际推理时,推理延时远远慢于BERT-Base。因此,针对模型进行优化时,需要综合不同的指标,分析模型的特点,找到模型的瓶颈,从而进行针对性的优化,才能对最终的推理性能有较大提升。
[Paper: Full Stack Optimization of Transformer Inference: a Survey] Figure 6 9
3. Efficient Transformer
虽然当前很多SOTA模型都是基于Transformer,而且很多大模型也都是以Transformer为基础,但是由于Transformer相对于输入序列的平方的复杂度,使得在很多需要长序列的场景中,比如处理图片、视频时受到很大的限制,因此很多方法被提出来改善模型的复杂度,比如降低模型的时间复杂度,减少模型的参数量,设计更适合于硬件的模型来减少访存等。本章节从三个不同角度来讨论使得模型在设计上更加高效的方法。
3.1 Efficient Attention
注意力机制作为Transformer的核心,它使得模型可以捕捉全局信息,进行长距离建模。但是注意力机制最核心的操作是进行矩阵相乘,由于词向量维数一般固定且不是很大,可以认为是常数,因此时间复杂度可以认为是输入序列长度的平方。本节讨论一些方法,侧重于改善注意力机制的时间复杂度,并根据核心思想进行分类和总结。
Blog: Transformers大家族——Efficient Transformers: A Survey
Blog: 「ArXiv2020」【Efficient Transformers: A Survey】论文笔记(更新中)
Fixed Patterns
将注意力机制从全局变为局部,限制注意力机制的范围,从而降低复杂度。根据限制的范围和形式,可以分为blockwise pattern, strided pattern,compressed pattern。
Blockwise pattern将输入序列切成多个block,只在每个block内部进行注意力机制的计算,显著降低了计算复杂度,比如Blockwise Attention、Local Attention等。但是这样简单的切割会导致序列不连贯,缺乏block之间的信息交互,注意力机制能力有限。虽然很简单,但是确实后续很多改进的基础。
Strided pattern采用滑动窗口的形式,每个token与周围相邻的几个token计算注意力,即按固定间隔进行注意力机制的计算。比如,Sparse Transformer使用类似strided形式的滑动窗口,LongFormer使用类似dilated形式的滑动窗口。相较于Blockwise pattern,考虑到自然语言很多情况下都是局部相关性较高,因此在一个窗口范围内计算注意力可能不会丢失太多信息。
Compressed pattern则是先通过卷积、池化等CNN操作进行下采样,从而有效减小序列长度,将输入序列转换到固定的模式,降低计算注意力机制的复杂度。
Blockwise attn: Blockwise Self-Attention for Long Document Understanding
Local attn: Image Transformer
Sparse Trans: Generating Long Sequences with Sparse Transformers
LongFormer: Longformer: The Long-Document Transformer
Combination of Patterns
对于输入的token,可以在不同维度、不同区域上组合使用不同的注意力机制,从而学习到更好的特征。比如,Sparse Transformer将一半的注意力头使用strided pattern,另一半注意力头使用local pattern。类似的,在Axial Tranformer中不是像多数注意力模块一样先将多维输入展平,而是每次沿着特征图的单个维度计算自注意力,然后组合多个维度的特征图以得到覆盖全局感受野的特征图。
Axial Trans: Axial Attention in Multidimensional Transformers
Learnable Patterns
Learnable pattern是对fixed pattern的拓展,fixed pattern是提前规定好一些区域,在这些区域中进行注意力,而learnable pattern则是引入可学习参数,让模型自己找到计算注意力的区域,即以数据驱动的方式指导模型的学习过程。比如Reformer引入基于哈希的相似度度量方法来将输入进行切割,Routing Transformer对token向量进行k-means聚类,从而将整体序列分割为多个子序列。因此,从最后注意力计算的角度看,Learnable pattern与fixed pattern是一致的,都是通过将整体序列进行切分,只在子序列中计算注意力,不同的只是子序列的划分方式是提前确定的还是模型学习得到的。
Reformer: Reformer: The Efficient Transformer
Routing Trans: Efficient Content-Based Sparse Attention with Routing Transformers
Neural Memory
Neural memory类似于compressed pattern中先压缩再计算注意力的想法,Set Transformer中第一次使用了这种方法。具体而言,就是初始化k个untrainable向量(k«n),n个token embedding和这k个trainable向量计算注意力,压缩得到k个向量,然后k个向量再和n个向量计算注意力还原得到n个向量,达到抽取输入序列特征的目的。这k个untrainable向量就可以理解为memory,用于处理临时上下文信息。
Set Trans: Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks
Low-Rank
Low-rank通过矩阵压缩或矩阵近似来降低计算注意力的复杂度。假设$N$是序列长度,$d$是向量维度,$k$是矩阵压缩的超参数。在Linformer中观察到,经过softmax计算之后得到的$N \times N$的attention score矩阵是不满秩的,这意味着不需要一个完整的attention score矩阵,可以使用一个$N \times k$的矩阵来近似$N \times N$的attention score矩阵,同时需要将$N \times d$的key和value向量映射到$k \times d$维空间,由于$k$是固定的超参数,因此将注意力机制的复杂度降低到了线性级别。
Kernels
Blog: 线性Attention的探索:Attention必须有个Softmax吗?
Linear Trans: Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
之前的一些研究中提到制约注意力机制性能的关键因素是其中的softmax操作,Scaled-Dot Attention其实就是对value做加权平均,未来得到attention score,就必须先对query和key进行运算。但是,以核函数变换的形式可以得到一个更加通用的注意力机制的数学表达,通过将相似性度量拆分,可以实现注意力机制线性的复杂度(原来的相似度计算中,指数操作的存在使得query,key,value的矩阵操作无法使用结合律)。由于通过kernel方法计算得到的是注意力矩阵的一种近似形式,因此核方法也可以认为是一种特殊的low-rank方法。
Recurrence
Recurrence实际上也是fixed pattern中blockwise的一种延申,本质上仍是对输入序列进行区域划分, 只是它进一步对划分后的block做了一层训练连接,通过这样的层级关系就可以把一个长序列的输出得到更好的表征。Transformer-XL使用segment-level recurrence,将上一个segment的状态缓存下来,然后再计算当前segment的时候重复使用上一个的隐藏状态,虽然加快了推理速度,但是由于需要进行缓存,是一种空间换时间的方案。
Transformer-XL: Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
3.2 Efficient Architecture Design
除了改善Transformer中注意力机制的复杂度,修改Transformer中其他部分可能同样有效。实际上,比如针对Bert-Base而言,从参数量的角度看,模型总的参数量约为104MB,其中多头注意力机制部分的参数量大约为27MB;从计算量和访存量的角度看,即使针对较长的序列而言,多头注意力机制部分也只是占了整个模型计算量/访存量的一半左右。因此,设计更加高效的网络架构,同样可以提高模型运行时的性能。同样,本节根据不同模型架构的设计思路和特点进行分类总结。
Blog: Hydra Attention: Efficient Attention with Many Heads翻译
Blog: 一文懂“NLP Bert-base” 模型参数量计算
[Paper: Full Stack Optimization of Transformer Inference: a Survey] Table 3
增加感受野
通过增加感受野,模型可以处理更加高分辨率的图像,但同时需要尽量降低额外带来的计算量。Efficient-ViT使用MobileNetV2中的MBConv作为基本块,使用线性注意力机制替代传统注意力机制,并且在前馈神经网络中使用可变形卷积。EdgeNeXt与之相似,它使用分裂的深度转置注意力模块(Split Depth-wise Transpose Attention, SDTA)来替代传统的多头注意力机制,SDTA将输入通道分成多个通道组,利用深度可分离卷积和跨通道的自注意力来有效增加模型的感受野。
[Paper: EfficientViT: Lightweight Multi-Scale Attention for On-Device Semantic Segmentation]
[Paper: EdgeNeXt: Efficiently Amalgamated CNN-Transformer Architecture for Mobile Vision Applications]
[Paper: MobileNetV2: Inverted Residuals and Linear Bottlenecks]
使用池化层
通常在注意力机制之后使用池化层,来减少推理延迟。NextViT交替使用卷积块和注意力块,其中卷积块由多头卷积注意力和MLP构成,卷积块主要使用了多头自注意力机制,但是注意力机制中key和value都先经过了一个池化层。PoolFormer总结了一种成为MetaFormer的通用架构,通过使用不同的Token-Mixer可以获得不同的具体架构,当Token-Mixer被修改为一个简单的池化层时,PoolFormer以极少的参数同样获得了与其他模型相似的准确度。
[Paper: Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios]
[Paper: MetaFormer Is Actually What You Need for Vision]
使用局部特征
LeViT再次将充分使用CNN的局部特征,尤其是首先通过卷积来得到低分辨率的特征图,然后通过修改注意力模块进行特征图的下采样。MobileViT网络主要使用MobileViT块和MBConv块堆叠而成,其中MobileViT块负责进行全局信息与局部信息的交互,其中将特征图通过卷积层进行局部建模得到局部信息,然后将局部信息的特征图基于注意力机制进行全局建模,最后进行残差连接。
[Paper: LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference]
[Paper: MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer]
保持维度一致性
相对于多头注意力机制角度的计算量对于推理延迟的影响,特征维度一致性对推理延迟同样甚至有更大的影响,比如网络中存在大量低效的reshape操作,反复调整特征的维度,会极大影响推理的速度。EfficientFormer提出了一种维度一致性的设计,将网络分成一个特征图为四维的部分和一个特征图为三维的部分,网络从patch embedding开始,首先进入四维特征图部分,最后进入三维特征图部分。在四维特征图部分,主要通过卷积结构为主;在三维特征图部分,此时网络结构中加入注意力机制和MLP结构。最终四维和三维分区的长度是通过网络架构搜索得到的。
[Paper: EfficientFormer: Vision Transformers at MobileNet Speed]
并行网络
一些模型可以并行的执行特定的层,从而加快推理速度。比如Mobile-Former的两个并行分支分别提取局部和全局信息,通过双向桥接进行信息的双向融合。MixFormer基于并行分支设计,将局部自注意力和通道分离卷积两个分支进行交互,并且根据不同分支上操作共享参数的维度不同,使用双向交互模块融合不同维度的信息,针对每个分支提供互补的信息来进一步学习到更好的特征。
[Paper: Mobile-Former: Bridging MobileNet and Transformer]
[Paper: MixFormer: Mixing Features across Windows and Dimensions]
3.3 Efficient Efforts
除了针对注意力机制和Transformer的架构进行改进,通用的模型压缩同样可以提高Transformer的推理性能,同时保持模型精度或将模型精度的下降控制在一个合理范围内。模型压缩主要包括剪枝、蒸馏、量化等。其中,剪枝和蒸馏可以减少模型参数量,量化可以提高模型的访存效率,而且不同的方法可以是正交的,即可以先进行模型的剪枝,再进行模型的量化。许多研究提出了不同的方法来进行Transformer模型的压缩,本节简单进行介绍。由于在自然语言处理领域和计算机视觉领域中,模型压缩的方法可能略有不同,本节更加侧重于视觉方面的模型压缩方法。
此外,由于Transformer的广泛应用,为了提高模型的推理性能,在设计模型架构时有时需要将硬件也纳入考虑,比如考虑到硬件限制的网络架构搜索,软硬件协同设计等,虽然本综述不涉及硬件的描述,但是本节最后介绍一种针对GPU的新型注意力机制FlashAttention,通过优化注意力机制算法的访存过程,来显著提高模型的运行速度、降低所需内存,同时保持对结果不变和对用户的透明。
3.3.1 Pruning
剪枝方法基于lottery ticket假设,即模型中只有小部分参数起到了核心作用,其他的大部分参数都是无效参数或是不重要的参数,可以去除掉,在减小模型参数量的同时,保持模型原有的精度。剪枝可以分为结构化剪枝与非结构化剪枝。非结构化剪枝允许修建任何参数,定位参数中接近于0的参数,将这些参数归零,使得权重矩阵稀疏化。虽然非结构化剪枝可以极大减少模型参数,但是由于硬件的限制,很多场景中无法完全发挥非结构化剪枝的效果。结构化剪枝是粒度较大的剪枝,修剪模型中结构化的部分,比如权重的整行,多头注意力中不需要的注意力头,多层Transformer中不需要的若干层等。由于存在一定限制,结构化剪枝的模型压缩率较小,但是更加适合于硬件运行。
考虑到Transformer中大部分的计算量是在多头注意力(MSA)和前馈神经网络(FFN)部分,为了简Transformer的结构,Vision Transformer Pruning(VTP)是第一个专门用于Vision Tranormer的剪枝方法。VTP首先使用L1稀疏正则化进行训练,VTP获取每一个Transformer block中Dimension的重要性分数,然后对分数较低的Dimension进行裁剪,这样大量的不重要的Dimension将会被裁剪,最后进行微调。不同于VTP主要关注于通道维度的冗余,PS-ViT方法关注于patch层面的冗余,通过计算patch对于最终分类特征的重要性得分来判断每个patch的有效性,同时保证信息一致性,显著降低了计算量并保持了原始模型的精度。NViT在剪枝时将模型的推理时间纳入考虑,通过重分配使用的参数,进行全局结构性剪枝。后续模型分别针对剪枝范围和粒度、剪枝方法、剪枝过程等做出改进,进一步提高模型的推理性能。
[Paper: THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS]
[Paper: Vision Transformer Pruning]
[Paper: Vision Transformer with Progressive Sampling]
[Paper: NViT: Vision Transformer Compression and Parameter Redistribution]
3.3.2 Distillation
蒸馏是指用教师模型来指导学生模型训练,通过蒸馏的方式让学生模型学习到教师模型的知识。在模型压缩中,教师模型是一个提前训练好的复杂模型,而学生模型则是一个规模较小的模型。由训练好的教师模型,在相同的数据下,通过将教师网络对该样本的预测值作为学生模型的预测目标指导学生模型学习。通过教师模型的指导,让学生模型学习教师模型的泛化能力,以达到或媲美教师模型的准确度。
在计算机视觉领域,DeiT在ViT的基础上,提出了一种专门针对Transformer的蒸馏方法,将distillation token与原始的class token同时加入网络,同时对损失函数进行相应的变化,显著减小了模型训练时间和训练所需的数据量。Mainfold Distiallation方法考虑了视觉Transformer的特点,在模型中间层引入了patch层级的细粒度监督信号,它是一种基于内积计算特征空间的流形结构表示,通过约束学生模型与教师模型的特征空间具有相似的流形结构,可以更好的将教师模型的知识迁移到学生模型中。TaT中进一步考虑到,由于教师模型和学生模型在结构上的异构型,直接对比像素级别的特征图可能导致不对齐的问题,因此使用注意力机制来隐式对齐语义,并提出一种近似的方法来改善方法的复杂度。
[Training data-efficient image transformers & distillation through attention]
[Learning Efficient Vision Transformers via Fine-Grained Manifold Distillation]
[Knowledge Distillation via the Target-aware Transformer]
3.3.3 Quantization
量化的基本思想即使用低精度、低比特的数据类型来代替原本的浮点数据类型,可以量化参数权重,也可以量化激活值,不但显著减小了模型的体积,更为重要的意义是优化了模型在运行时的访存,相较于单个指令的计算,访存耗时要远高于计算,因此可以显著加速模型推理。量化最核心的挑战在于使用更低精度的权重的同时保持模型精度尽可能少的降低。量化主要分为两大类,训练后量化(Post-Training Quantization,PTQ)和量化感知训练(Quantization-Aware Training,QAT)。训练后量化是将训练好的模型中的参数或激活值量化为低精度类型的数值类型,虽然使用简单,但是模型精度精度下降一般要高于量化感知训练。量化感知训练在训练过程中模拟量化过程,进而在更新参数时考虑量化产生的误差,虽然量化感知训练得到的量化模型精度下降较低,但是因为需要重新训练,所以开销较大,在实际使用中需要进行权衡使用。
虽然在卷积神经网络中可以相对简单的使用量化,但是将量化应用于Transformer存在一些挑战。Transformer激活值范围较大,很难使用低精度数据类型表示。传统的卷积神经网络会将异常的离群值截断,但是在Transformer中,这样的离群值有助于深层网络中形成特定的注意力模式,直接截断会改变网络的特性和精度,如果不截断会导致数值分辨率降低,而且注意力机制中存在一些难以量化的算子,进一步导致Transformer模型难以量化。PTQ4ViT提出了使用孪生均匀量化方法来解决激活值范围大的问题,同时为了获得最优的量化参数(而非局部最优),使用Hessian引导度量来评估不同的标定因子,从而以较小的成本提高校准准确率,最终达到了近乎无损的量化效果。针对部分算子难以量化的问题,FQ-ViT中使用Power-of-Two Factor(PTF)来量化LayerNorm,使用Log-Int-Softmax(LIS)来量化softmax,并使用4位量化和BitShift来进行简化,这也是第一个实现Transformer无损全量化的工作。
[Understanding and Overcoming the Challenges of Efficient Transformer Quantization]
[PTQ4ViT: Post-Training Quantization Framework for Vision Transformers with Twin Uniform Quantization]
[FQ-ViT: Post-Training Quantization for Fully Quantized Vision Transformer]
3.3.4 FlashAttention
FlashAttention是一种对标准注意力机制进行加速的算法,减少了对HBM(High Bandwidth Memory,通常用于GPU显存)的访问,而且它的训练和推理过程的结果和标准注意力机制完全相同,对用户透明,并且显著减小了标准注意力机制的运行时间和所需内存。
FlashAttention主要从两个方面减少注意力机制的HBM的访问。首先在计算softmax时,FlashAttention可以在不访问整个输入的情况下计算softmax reduction,将输入分割成块,在输入块上多次传递,从而以增量的方式计算softmax reduction。其次,在传统注意力机制中,需要将$QK^T$的计算结果$S$和$softmax(S)$后的计算结果$P$分别存储到显存中,FlashAttention对此做出改进,在反向传播中不存储中间注意力矩阵,避免从显存中读取和写入中间结果矩阵。通过分块写入到HBM中去,存储前向传递的 softmax 归一化因子,在后向传播中快速重新计算片上注意力,这比从HBM中读取中间注意力矩阵的标准方法更快。即使由于重新计算导致 FLOPS 增加,但因为减少了HBM访问,导致运行速度更快并且使用更少的显存(序列长度线性)。
此外,最新的研究SCFA进一步进行拓展,使得FlashAttention可以计算稀疏注意力,特别是针对Hash-based Attention和Query/Key-Dropping Based Attention,都得到了显著的推理加速。
Blog: 论文分享:新型注意力算法FlashAttention
[Paper: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness]
[Paper: Faster Causal Attention Over Large Sequences Through Sparse Flash Attention]
4. Discussion on Future Research
Transformer虽然有很强的建模能力,但是由于其中注意力机制具有序列长度平方的复杂度,限制了Transformer在很多场景中的使用。在未来的工作中,仍然可能会有很多工作对efficient attention、efficient transformer、模型压缩的不同方面进行改进。除此之外,本文观察到另外两个方向未来可能有进一步的发展。
4.1 Early Exit
虽然当前很多研究关注于大模型在大量数据上的有效训练,但是经过训练的模型在实际使用中仍然速度较慢,特别是大模型作为基础设施时,越来越多的关注集中于提高模型的推理速度上。从模型来分析,很多大语言模型都是自回归模型,需要根据前面的单词递推的预测下一个单词,这个过程不能并行化,而且考虑到大模型庞大的参数量,整个推理过程需要大量的计算与较高的延迟。
在推理时,有些单词的预测比较轻松,可能在比较浅层的网络中就可以预测出正确的结果,不用计算到最后一层就可以正确预测,即提前退出(early exit),有的单词就需要较多的计算才能预测,但是很多模型在推理时针对这两种情况使用了相同的计算量。有一些工作已经初步在这方面进行了尝试,比如CALM,不是等待所有解码器层完成,而是尝试在某个中间层之后更早地预测下一个单词。 为了决定是进行某个预测还是将预测推迟到后面的层,测量模型对其中间预测的置信度。 只有当模型有足够的信心预测不会改变时,才会跳过其余的计算。
[Paper: Confident Adaptive Language Modeling]
4.2 Alternatives to Attention
虽然注意力机制对于Transformer而言至关重要,但是由于其较高的复杂度,一些研究开始寻找注意力机制的替代而非单纯改进注意力机制。在AFT模型中,同样有类似于标准的点积注意力算法,同样由查询向量Q,被查向量K,内容向量V相互作用而成。但不同的是,AFT中的K和V首先与一组学习得到的位置偏差(position bias)结合,然后再进行同位元素对应相乘(element-wise multiplication)。这一新操作的内存复杂度、文本规模、特征维度都是线性的。当前一个较新的尝试是Hyena。Hyena将时域卷积和频域卷积作为一个组合,通过递归进行多次来增大表达能力,其全局卷积网络达到了超越Transformer建模的效果。
[Paper: An Attention Free Transformer]
[Paper: Hyena Hierarchy: Towards Larger Convolutional Language Models]
5. Conclusion
在本综述中,从推理的角度出发,对efficient transformer进行了粗粒度的调研、分析与总结,并且相对侧重于计算机视觉方面的研究。首先介绍模型不同角度的efficiency和评价efficiency的量化指标。然后从模型算法的角度,从不同层次分析了当前提高模型效率的方法,比如设计复杂度更低的注意力机制,更加高效的网络设计,模型压缩和优化等方法,并针对每种方法进一步做了分类和总结,选取代表性的方法进行具体说明。最后,简单讨论了一些efficient transformer未来可能的发展方向,比如早退机制、注意力机制的替代品等。
6. More Reading
Large Transformer Model Inference Optimization
The Transformer Family Version 2.0