内存模型
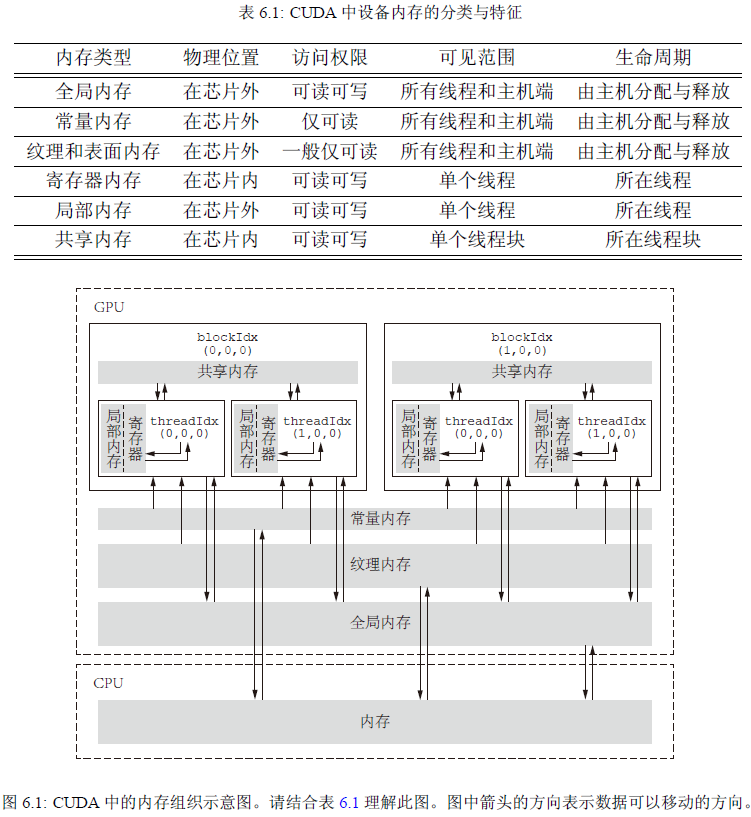
全局内存
对全局内存变量的理解:
- 从主机端看,全局内存变量只是一个指针,主机端不知道其指向何方。主机端也无法进行操作
- 从设备端看,即为全局内存变量
- 一个经常会发生的错误就是混用设备和主机的内存地址:主机代码不能直接访问设备变量,设备也不能直接访问主机变量
对全局内存的读写
- 如果是读操作,有三种部分的访问方式:
- L1缓存,L2缓存,DRAM
- (禁用L1缓存)L2缓存,DRAM
- Fermi之后都是默认禁用L1
- 禁用L1缓存的原因是,L1缓存被用作缓冲从寄存器中溢出的数据
- 只读缓存,L2缓存,DRAM
- 如果是写操作,则无法被缓存,只经过device层次的L2缓存,没有命中再访问DRAM
- ==不是很清楚==
- 如果是读操作,有三种部分的访问方式:
编程模型
- 动态全局内存:
| |
- 静态全局内存:
- 如果静态全局变量是一个变量(而非数组类型):此时主机中不可以直接给静态全局内存变量赋值,可以通过
cudaMemcpyToSymbol()和cudaMemcpyFromSymbol()拷贝。 (一个例外:固定内存)1 2 3 4 5 6 7 8 9__device__ double d; // 从设备端来看,d直接就是设备全局内存上的变量;从主机端来看,d是一个指针,但是不知道其指向哪里 double h = 0.0; cudaMemcpyToSymbol(d, &h, sizeof(double)); // H2D cudaMemcpyFromSymbol(&h, d, sizeof(double)); // D2H // 因为使用cudaMemcpy需要得到d的地址,而主机端无法直接操作设备端的变量。如果非要使用cudaMemcpy: double *dptr; cudaGetSymbolAddress((void**)(&dptr), d); // 因为主机无法对全局内存变量d取地址,只能使用函数间接得到其地址dptr cudaMemcpy(dptr, h, 100*sizeof(double), cudaMemcpyToDevice); - 如果静态全局变量是一个数组,可以使用
cudaMemcpy:1 2 3__device__ double d_x[100]; // d_x[]直接就是设备全局内存上的数组,d_x是其地址 double h_x[100]; cudaMemcpy(d_x, h_x, 100*sizeof(double), cudaMemcpyHostToDevice);
- 如果静态全局变量是一个变量(而非数组类型):此时主机中不可以直接给静态全局内存变量赋值,可以通过
优化
全局内存访问速度慢,往往是一个 CUDA 程序的性能瓶颈。 优化目标:
- 对齐合并的内存访问,减少带宽浪费
- 足够的并发内存操作,隐藏内存延迟
全局内存的对齐合并访问
访问粒度:
- L1的缓存粒度为128字节(可以禁用L1缓存,只使用L2缓存)
- L2的缓存粒度为32字节
- 只读缓存也可以缓存全局内存中的数据,缓存粒度为32字节
- 使用
__ldg()函数将全局内存缓存到只读缓存中 - 如果编译器能够判断一个全局内存变量在整个核函数的范围内都可读,则自动使用
__ldg()函数进行缓存,但是对于全局的写入,没有相应的函数 - 可以使用
__restrict__修饰指针,表示该指针专门用来访问特定的数组(该指针不是别名),nvcc使用只读缓存进行加载
- 使用
内存对齐:
- 一次数据传输中,从全局内存转移到 L2 缓存的一片内存的首地址一定是 32 的整数倍。
- 使用cuda runtime api(比如cudaMalloc)分配的内存的首地址至少是256字节的整数倍
内存事务:从核函数发起请求,到硬件相应返回数据这个过程
- 内存事务可以分为1段,2段,4段
- 比如全局内存写入时,经过L2缓存,缓存粒度为32字节,此时一次内存事务可以写入1段32字节,2段64字节,4段128字节,其他字节数量只能组合得到
全局内存的访问模式:
- 对齐的:内存事务的首地址是缓存粒度的整数倍
- 合并的(coalesced):一个warp对全局内存的访问都在一个缓存粒度中(一个warp对全局内存的访问导致最少数量的数据传输),或者可以理解为缓存利用率
- 合并度=$\frac{warp请求的字节数}{由该请求导致的所有数据传输的字节数}$
几种常见的内存访问模式:(以一维的grid和一维的block为例)
- 理想的内存访问:顺序的合并访问,合并度=100%
1 2 3 4 5void __global__ add(float *x, float *y, float *z){ int n = threadIdx.x + blockIdx.x * blockDim.x; z[n] = x[n] + y[n]; } add<<<128, 32>>>(x, y, z);- 乱序的合并访问:访问是交叉的,但仍是合并的,合并度=100%
1 2 3 4 5 6 7void __global__ add_permuted(float *x, float *y, float *z){ int tid_permuted = threadIdx.x ^ 0x1; // 交换两个相邻的数 // 比如:threadIdx.x=0, tid_permuted=1; threadIdx.x=1;tid_permuted=0; int n = tid_permuted + blockIdx.x * blockDim.x; z[n] = x[n] + y[n]; } add_permuted<<<128, 32>>>(x, y, z);- 不对齐的非合并访问(地址错位)
- 如果使用L1 cache,访问粒度为128字节,速度快,但是带宽利用率更低
- 如果不使用L1 cache,访问粒度为32字节,速度慢,但是带宽利用率更高,从而可以提高总线的整体利用率
1 2 3 4 5 6 7 8void __global__ add_offset(float *x, float *y, float *z){ int n = threadIdx.x + 1 + blockIdx.x * blockDim.x; z[n] = x[n] + y[n]; } add_offset<<<128, 32>>>(x, y, z); // 对于某个thread block,有32个线程 // 假设数组x,y,z首地址都是256字节的倍数,而一次访存至少32字节 // 由于地址错位,需要进行五次访存,合并度=128/(5*32)=80%- 跨越式非合并访问
- 如果使用L1 cache,访问粒度为128字节,合并度很低(而且出现频繁的缓存失效和替换)
- 如果不使用L1 cache,访问粒度为32字节,合并度稍微提升
1 2 3 4 5 6 7 8void __global__ add_stride(float *x, float *y, float *z){ int n = blockIdx.x + threadIdx.x * gridDim.x; z[n] = x[n] + y[n]; } add_stride<<<128, 32>>>(x, y, z); // 对于0号线程块(blockIdx.x=0),将访问:0, 128, 256, 384 ... 等位置 // 即stride=gridDim.x=128 // 合并度=128/(32*32)=12.5%,触发32次访存,每次访存32字节- 广播式非合并访问
1 2 3 4 5 6 7void __global__ add_broadcast(float *x, float *y, float *z){ int n = threadIdx.x + blockIdx.x * blockDim.x; z[n] = x[0] + y[n]; } // 合并度=4/32=12.5% // 虽然合并度低,但是整个过程只进行了一次访存 // 其实更适合使用常量内存
定量衡量核函数的有效带宽
带宽:
- 理论带宽:硬件限制
- 有效带宽:核函数实际达到的带宽,$有效带宽=\frac{(读字节数+写字节数)\times 10^{-9}}{运行时间}$
- 吞吐量:单位时间内操作的执行速度,比如说FPS或(流水线)每个周期完成都少个指令,不仅取决于有效带宽,而且与带宽的利用率、是否命中缓存有关
- 比如数据经常命中缓存,此时吞吐量就可能超过有效带宽
例子:使用全局内存进行方阵转置,
- 准备工作:测量有效带宽的上限和下限
- 测量有效带宽的上限:对A按行合并读取,对B按行合并写入
1B[nx + ny * N] = A[nx + ny * N]; - 测量有效带宽的下限:对A按列交叉读取,对B按列交叉写入
1B[ny + nx * N] = A[ny + nx * N];
- 测量有效带宽的上限:对A按行合并读取,对B按行合并写入
- 测试:code部分如果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16const int TILE_DIM = 32; const int N = 100; typedef double real; __global__ void copy(const read *A, real *B, const int N){ const int nx = threadIdx.x + blockIdx.x * TILE_DIM; const int ny = threadIdx.y + blockIdx.y * TILE_DIM; /* code */ } const dim3 block_size(TILE_DIM, TILE_DIM); // 每个thread block中TILE_DIM*TILE_DIM个线程,每个元素对应一个线程 // 此时一个线程块中32*32个线程,少于1024的限制 const dim3 grid_size((N + TILE_DIM - 1) / TILE_DIM, (N + TILE_DIM - 1) / TILE_DIM); // grid的维度 copy<<<grid_size, block_size>>>(A, B, N);将A的一行转成B的一列:
1 2if(nx < N && ny < N) B[ny + nx * N] = A[nx + ny * N];- 对于A的读取是顺序的,对于B的写入是非顺序的
将A的一列转成B的一行:更快
1 2if(nx < N && ny < N) B[nx + ny * N] = A[ny + nx * N];- 对于A的读取不是顺序的,对于B的写入是顺序的
分析:
如果对A按行读取(将A的一行转成B的一列),对A按行读取是合并的,写入过程(交叉写入)不缓存
如果对B按行写入(将A的一列转成B的一行),对A按列读取是交叉的,写入过程(合并写入)不缓存,应该更慢
但是实际上第二种方式更快,原因在于L1缓存命中率
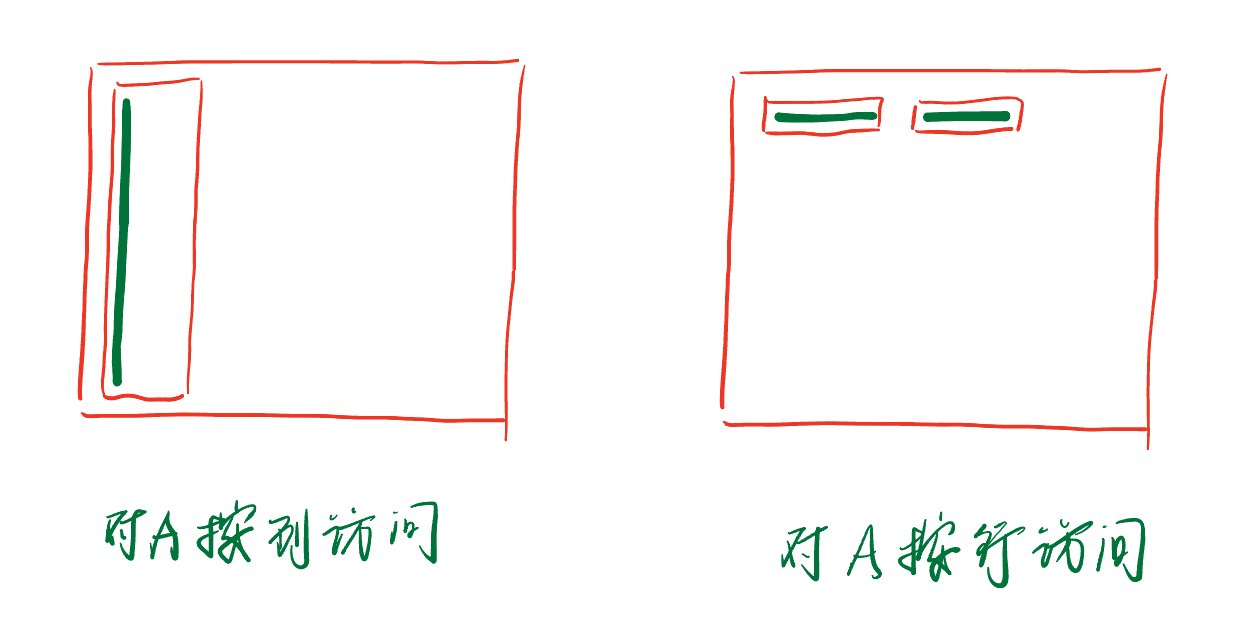
- 对A按行读取,每个warp读取$32\times4B=128B$,正好是一次L1缓存的访问粒度,相当于每次访问,L1缓存命中率都为0,数据从全局内存拿到L1缓存后,后续这些数据又不再使用。因此,总体来看L1缓存命中率=0
- 对A按列访问,第0个warp中每个线程此时都L1缓存没有命中,此时会有32次128B的访存,然后数据拿到L1缓存中,后面第1~31个warp中线程都可以命中L1缓存。因此,总体来看缓存命中率=$\frac{31}{32}$=0.96875
- 可能是对A按列访问由于L1缓存命中率高,隐藏延迟更好,总体耗时更短,==不是很清楚==
若不能满足读取和写入都是合并的,一般应该尽量做到合并写入
- 准备工作:测量有效带宽的上限和下限
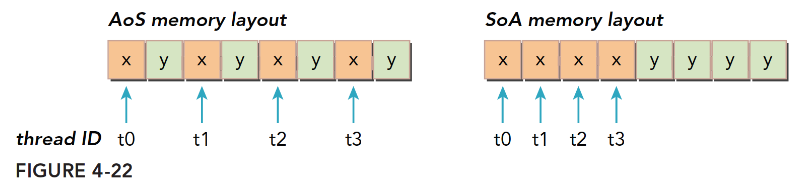
结构体数组和数据结构体
结构体数组(Structure of Array,SoA):一个结构体,其中成员是数组
1 2 3 4 5struct SoA{ int a[N]; int b[N]; }; struct SoA myStruct;数组结构体(Array of Structure, AoS):一个数组,每个元素都是一个结构体
1 2 3 4typedef struct element { int a, b; } Aos; Aos array[N];CUDA中普遍倾向于SoA(结构体数组)因为这种内存访问可以有效地合并
其他
增加每个线程中执行独立内存操作的数量,减少核函数发射的数量
- 对于IO密集型的核函数,每个线程多处理一点数据(而非原来只处理一个数据)
- 比如reduce中,每个线程可以先累加多个数据,然后再进行两两数据的折叠相加
对核函数的运行配置进行调整,提升SM占用率
- 提升SM占用率会更好隐藏访存延迟吗?==不是很清楚==
- 参考:
Better Performance at Lower Occupancy
- 参考:
- 提升SM占用率会更好隐藏访存延迟吗?==不是很清楚==
参考
常量内存
- 常量内存属于全局内存,只有64KB
- 核函数的参数通过常量内存传递,且限定4KB
- 常量内存通过Read-Only Data Cache进行缓存,而且读取到的数据可以广播给warp中的其他线程
- 因为是只读的,因此常量内存必须在全局空间内、所有核函数之外进行声明,且必须在kernel启动前由host进行初始化(比如使用
cudaMemcpyToSymbol来进行初始化)
纹理和表面内存
- 纹理内存专门为那些存在大量空间局部性的内存访问模式设计,可以充分利用空间局部性(比如插值、滤波等操作)
- 纹理内存驻留在全局内存中,经过只读纹理缓存进行缓存
寄存器
- 一个寄存器有32bit(4B)的大小,一些常用内建变量存放在寄存器中
- 核函数中定义的不加任何限定符的变量一般就存放在寄存器中,不加任何限定符的数组可能存放在寄存器中,或者放在局部内存中(即寄存器溢出,会对性能造成很大影响)
- 核函数前显式说明来帮助编译优化:
__launch_bounds_(maxThreadaPerBlock, minBlocksPerMulitprocessor)maxThreadaPerBlock:线程块内包含的最大线程数minBlocksPerMulitprocessor:可选参数,每个SM中预期的最小的常驻线程块数量
- 寄存器只能被一个线程可见,因此每个线程都有一个变量的副本,而且该变量的副本可以值不同
局部内存
- 将寄存器放不下的变量、索引值不能再编译时就确定的数组,都存放在局部内存中(编译器进行判断)
- 局部内存是全局内存的一部分,因此使用时延迟较高
- 对于计算能力2.0以上的设备,局部内存可能会存储在L1缓存或L2缓存上
共享内存
- 主要作用:
- 减少核函数中对全局内存的访问次数,实现高效的线程块内部的通信
- 优化对全局内存的访问模式,尤其是针对全局内存的跨越式非合并访问,提高带宽利用率
- 共享内存一般和L1缓存共享64KB片上内存,可以进行配置
- 按设备进行配置
1 2 3 4 5 6 7cudaDeviceSetCacheConfig(cudaFuncCache cacheConfig); /* 参数 cudaFuncCachePreferNone: no preference(default) cudaFuncCachePreferShared: prefer 48KB shared memory and 16 KB L1 cache cudaFuncCachePreferL1: prefer 48KB L1 cache and 16 KB shared memory cudaFuncCachePreferEqual: prefer 32KB L1 cache and 32 KB shared memory */ - 不同核函数自动配置
1cudaFuncSetCacheConfig(const void* func, enum cudaFuncCache cacheConfig); // 配置核函数func对应的共享内存大小
- 按设备进行配置
编程模型
- 静态分配:
__shared__ float mat[5][5]; - 动态分配:
- 函数内声明方式:
extern __shared__ double arr[];- 动态共享内存只支持一维数组
- 核函数的执行配置中,第三个参数为每个线程块中动态共享内存的字节数:
<<<grid_size, block_size, sizeof(float) * block_size>>>
- 函数内声明方式:
- 同步:
__syncthreads进行线程块的同步
优化
缓存
L1和L2缓存:缓存局部内存和全局内存的数据
- 每个SM都有自己的L1缓存,但是L2缓存是所有SM共用的
- 可以配置是否使用L1缓存
- CPU的L1缓存考虑了时间局部性(LRU算法)和空间局部性,GPU的L1缓存只有空间局部性,没有时间局部性(频繁访问一个一级缓存的内存位置不会增加数据留在缓存中的概率)
CPU的一级缓存是的替换算法是有使用频率和时间局部性的,GPU则没有
- 与CPU读写都缓存不同,GPU只会针对读过程进行缓存,写过程不缓存
每个SM都有一个只读常量缓存
- 使用
__ldg()函数显示将数据通过只读数据缓存进行加载
- 使用
GPU不是很强调缓存(not dependent on large caches for performance),因为当指令或数据miss时,由于warp切换速度快,所以旧切换warp;即用计算而非cache来隐藏延迟
内存管理

常规数据传输函数
cudaMalloc函数:cudaError_t cudaMalloc(void **address, size_t size);- 示例:
1 2double *d_x; cudaMalloc((void**)&d_x, 100); // &d_x的类型为double** - 参数说明:
address是在分配设备内存的指针
- 注意事项:
- ==一个经常会发生的错误就是混用设备和主机的内存地址==:主机代码不能直接访问设备变量,设备也不能直接访问主机变量
- 因为该函数的功能是改变指针
d_x的值(即改变d_x指向的位置,将一个指向内存地址的指针赋值给d_x),而非改变d_x所指内容的值,因此只能传入指针d_x的地址,即指针的指针 - 原来
d_x是主机上的一个指针,cudaMalloc之后改变为指向设备全局内存的指针,本质上是GPU地址在内存中的虚拟映射地址
- 示例:
cudaMemset函数:cudaError_t cudaMemset(void * devPtr,int value,size_t count)cudaFree函数:cudaError_t cudaFree(void* address)- 设备内存的分配和释放非常影响性能,尽量重用
- CUDA允许在核函数内部使用malloc/free 分配/释放全局内存,但是一般会导致较差的性能
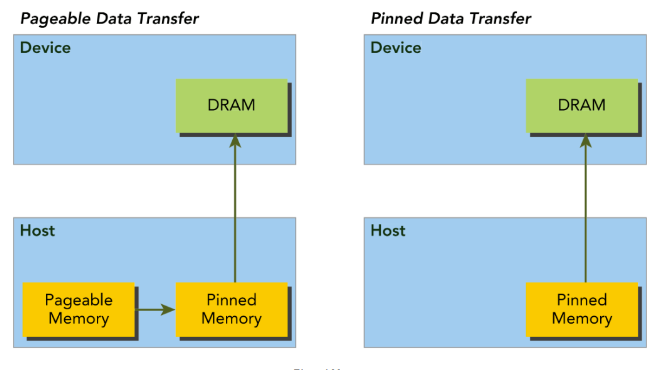
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind)- 主机端的内存默认是可分页的,如果进行数据拷贝,此时CUDA分配不可分页的固定内存,将可分页内存中的数据复制其中,然后再从固定内存中拷贝数据到显存
- 如果主机端的内存是可分页的,使用虚拟内存,当该页面被换出到交换区时,设备此时无法访问或者进行控制
cudaMemcpyToSymbol函数和cudaMemcpyFromSymbol函数- symbol是一个驻留在全局或常量内存空间中的变量
cudaMemcpy的异步版本cudaMemcpyAsynccudaError_t cudaMemcpyAsync(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind, cudaStream_t stream)- 使用异步的数据传输函数时,需要将主机内存定义为不可分页内存(使用
cudaMallocHost或cudaHostAlloc),从而防止在程序执行期间物理地址被修改 - 如果将可分页内存传递给
cudaMemcpyAsync,则会导致同步传输
固定内存:
cudaError_t cudaMallocHost(void **devPtr, size_t count);cudaError_t cudaFreeHost(void *ptr);- 固定内存的释放和分配成本比可分页内存要高很多,但是传输速度更快,所以对于大规模数据,固定内存效率更高。
- 固定内存有更高的读写带宽,但是分配过多的固定内存可能会降低主机系统的性能,同时固定内存分配和释放的代价更高。通常, 当传输数据量>=10M时, 使用固定内存是更好的选择
零拷贝内存
- 在零拷贝内存中,主机和设备可以直接访问对方的变量,原理是将host内存直接映射到设备内存空间上,使得设备可以通过DMA的方式访问host的锁页内存
cudaError_t cudaHostAlloc(void **pHost, size_t size, unsigned int flags)cudaHostAllocDefault:与cudaMallocHost函数行为一致cudaHostAllocPortable:返回能被所有CUDA上下文使用的固定内存,而不仅是执行内存分配的那一个,分配portable memory,适用于主机多线程,让控制不同GPU的主机端线程操作同一块portable memory,实现GPU线程间通信cudaHostAllocMapped:分配mapped memory,可以在kernel中直接访问mapped memory中的数据,不必再内存和显存之间进行数据拷贝,即zero-copy功能cudaHostAllocWriteCombined:分配write-combined memory,提高从CPU向GPU单向传输数据的速度,不使用CPU的L1、L2 cache,将cache资源留给其他程序使用,在PCI-E总线传输期间不会被来自CPU的监视打断- 将多次写操作写到固定内存的buffer中,将多次写合并;但实际上性能会比普通的write-back更糟糕, 主要是由于其没有使用cache, 而是直接写回内存
- 零拷贝内存虽然不需要显式的将主机的数据复制到设备上,但是设备也不能直接访问主机端的数据,需要通过
cudaHostGetDevicePointer函数主机上的地址,然后才能通过pDevice访问主机上的零拷贝内存cudaHostGetDevicePointer(void **pDevice, void *pHost, unsigned int flags);flags设置为0
- 如果使用统一内存,则无须使用
cudaHostGetDevicePointer
- 使用零拷贝内存需要注意同步主机和设备之间的内存访问
- 零拷贝内存适合用于少量的数据传输
统一内存
发展:
- 统一寻址(Unified Address):Fermi架构中提出了统一的地址空间,将全局内存、局部内存、共享内存放在一个地址空间中
- 统一虚拟地址(UVA):CUDA 4(开普勒架构,麦克斯韦架构)引入,将CPU和GPU的内存映射到统一的虚拟地址上,可以使用指针访问对方的地址
- 统一内存(UM):CUDA 6(帕斯卡架构之后)引入,实现了一个CPU和GPU之间的内存池
- 对于第一代统一内存,主机与设备不能并发访问统一内存。因此,在主机调用核函数之后,必须加上一个同步函数(比如
cudaDeviceSynchornize),确保核函数对统一内存的访问已经结束,然后才能主机访问统一内存变量 - 对于第二代统一内存,主机与设备可以并发访问统一内存
- 对于第一代统一内存,主机与设备不能并发访问统一内存。因此,在主机调用核函数之后,必须加上一个同步函数(比如
语法相关:
- 统一内存在device中当作全局内存来使用,必须由主机来定义或分配内存,不能在设备端(核函数或
__device_函数中)进行。因此,在核函数中由malloc分配的堆内存不属于同一内存,因而如果CPU需要访问,需要手工进行移动 - 同一个程序中可以同时使用统一内存和非统一内存
- 统一内存在device中当作全局内存来使用,必须由主机来定义或分配内存,不能在设备端(核函数或
统一内存的分配
- 动态分配:
cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned flags = 0);- 参数
flags默认为cudaMemAttachGlobal,表示分配的全局内存可以由任何设备通过任何CUDA流访问
- 参数
- 静态分配:
__device__ __managed__修饰,而且只能是全局变量
- 动态分配:
超量分配:
- 编译选项:
-DUNIFIED cudaMallocManaged申请内存只是表示预定了一段空间,统一内存的实际分配发生在第一次访问预留的内存时
- 编译选项:
优化使用统一内存的程序
- 可以手动给编译期一些提示,避免数据缺页、内存抖动,保持数据局部性等,可以使用
cudaMemAdvice和cudaMemPrefetchAsync cudaError_t cudaMemPrefetchAsync(const void *devPtr, size_t count, int dstDevice, cudaStream_t stream)- 在CUDA流中将统一内存缓冲区devPtr内count字节的内存迁移到设备dstDevice(
cudaCpuDeviceId表示主机的设备号)中的内存区域,从而防止或减少缺页异常,提高数据局部性 - 尽可能多的使用
cudaMemPrefetchAsync
- 在CUDA流中将统一内存缓冲区devPtr内count字节的内存迁移到设备dstDevice(
- 可以手动给编译期一些提示,避免数据缺页、内存抖动,保持数据局部性等,可以使用
优势:
- 简化编程
- 编程更简单:比如之前多GPU,针对某一个数据使用零拷贝内存,每个设备都需要有对应的一个指针,容易混乱(针对零拷贝的改进)
- 方便代码移植
- 支持更完整的C++语言要素:比如核函数参数可以使用引用,可以直接使用拷贝构造函数而不用手工进行拷贝或进行很多重载
- 可能会提供比手工移动数据更好的性能,比如可能会将某部分数据放置到离某个存储器更近的位置
- 可以进行超量分配,超出GPU显存的部分可以放在主机内存中(但是反过来不行)
- 简化编程