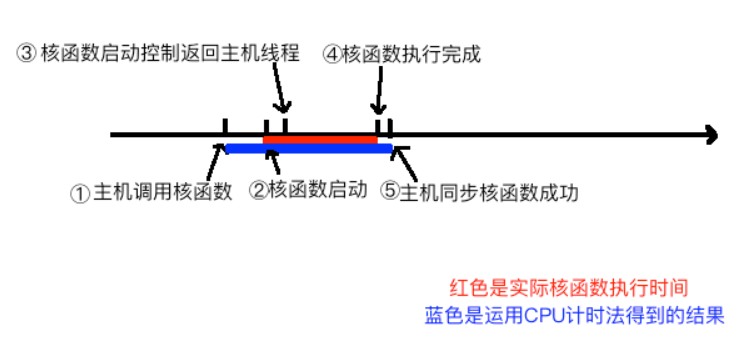
CUDA事件
- 事件:标记stream执行过程的某个特定的点,比如用于计时
| |
CUDA流
CUDA流:由主机发出的、在一个设备中执行的CUDA操作序列
kernal_func<<<grid_size, block_size, 0, stream>>>(params);- 一个CUDA流中各个操作的次序是由主机控制的,但是来自于两个不同CUDA流中的操作顺序无法确定
- 任何CUDA操作都存在于某个CUDA流中,要么是默认流(也成为空流),要么明确指定的流
相关函数
cudaError_t cudaStreamCreate(cudaStream_t *stream);cudaError_t cudaStreamDestory(cudaStream_t stream);cudaError_t cudaStreamSynchronize(cudaStream_t stream);- 同步等待一个流中的所有操作完成
cudaError_t cudaStreamQuery(cudaStream_t stream);- 查询一个流中的操作是否全部完成,不会阻塞;若是,则返回
cudaSuccess; 否则,返回cudaErrorNotReady。
- 查询一个流中的操作是否全部完成,不会阻塞;若是,则返回
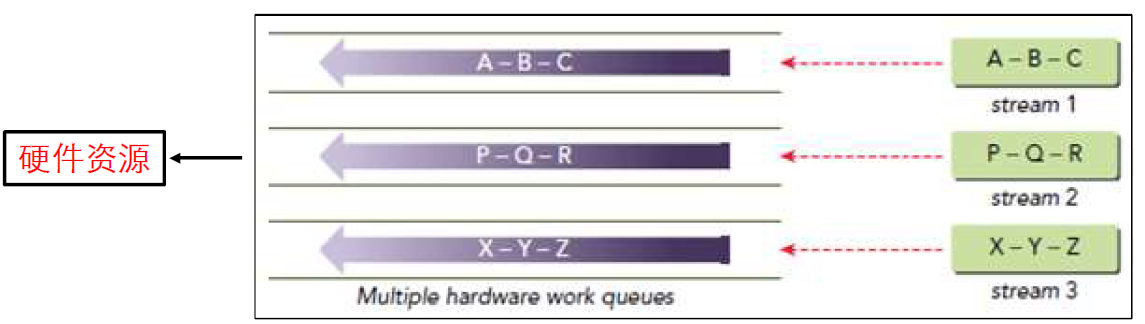
Stream对并行性的影响
- 调度队列的个数:
- 单调度队列:虽然Fermi架构支持最多16个流,但是实际调度过程中,所有的流被塞进同一个调度队列,当选中一个操作执行时,runtime会查看操作之间的依赖关系,如果当操作依赖于前面的操作,而且由于只有一个调度队列,因此调度队列阻塞(后面所有操作都等待,即使这些操作来自不同的流)

- Hyper-Q:最多32个调度队列和32个流
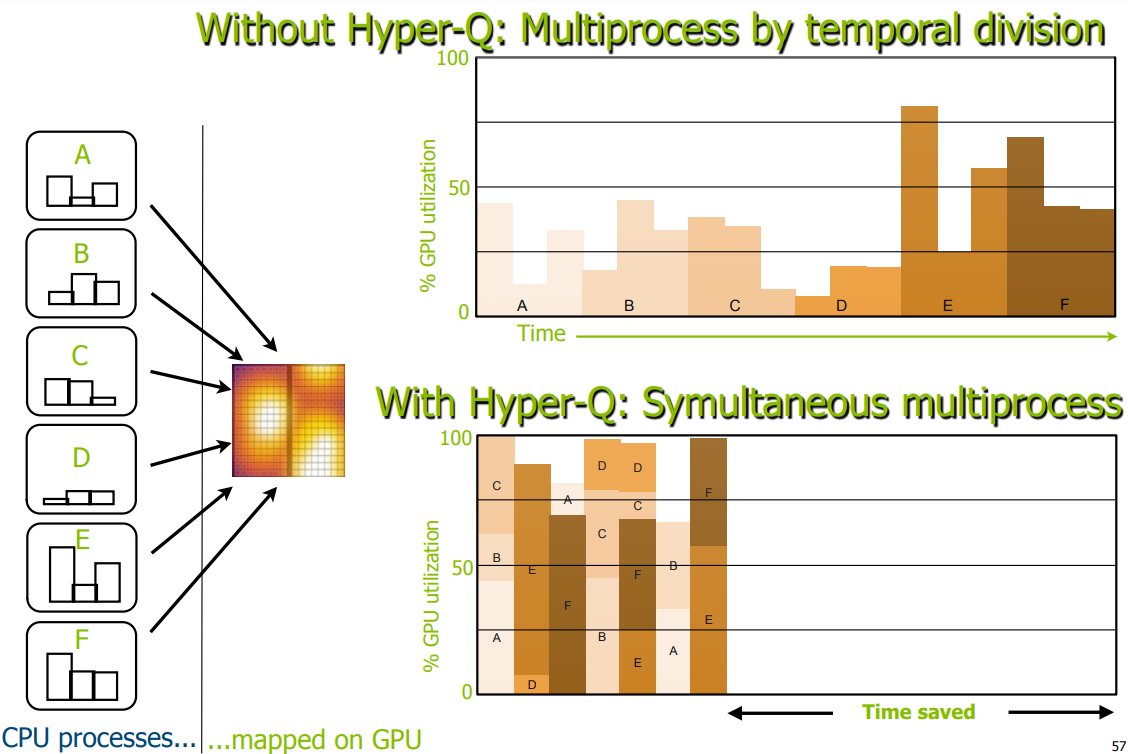
- 单调度队列:虽然Fermi架构支持最多16个流,但是实际调度过程中,所有的流被塞进同一个调度队列,当选中一个操作执行时,runtime会查看操作之间的依赖关系,如果当操作依赖于前面的操作,而且由于只有一个调度队列,因此调度队列阻塞(后面所有操作都等待,即使这些操作来自不同的流)
- 多个流的操作的发射顺序
- 左边将多个流以DFS方式发射,右边将多个流以BFS方式发射

- 以DFS方式发射时,流的发射顺序对并行性有影响
- 每种资源都有一个队列
- 每个流内部很可能有依赖关系
- 比如先发射Stream1,后发射Stream2:
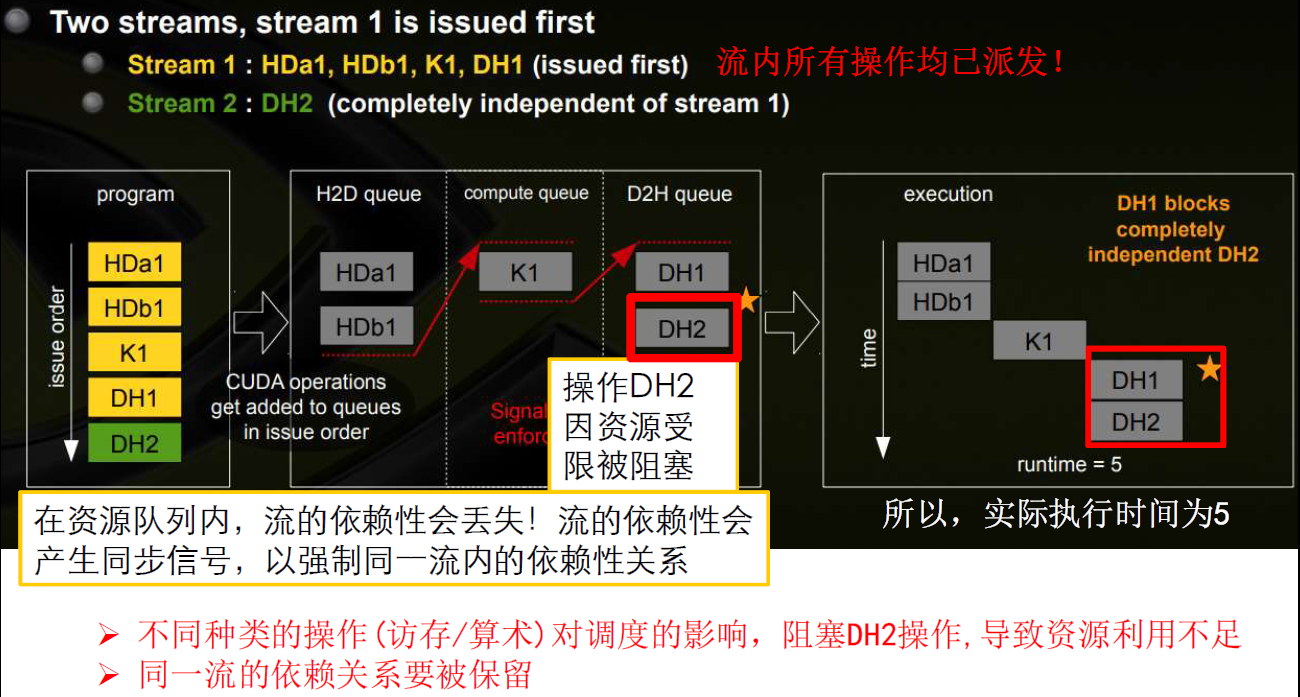
- 比如先发射Stream2,后发射Stream1:
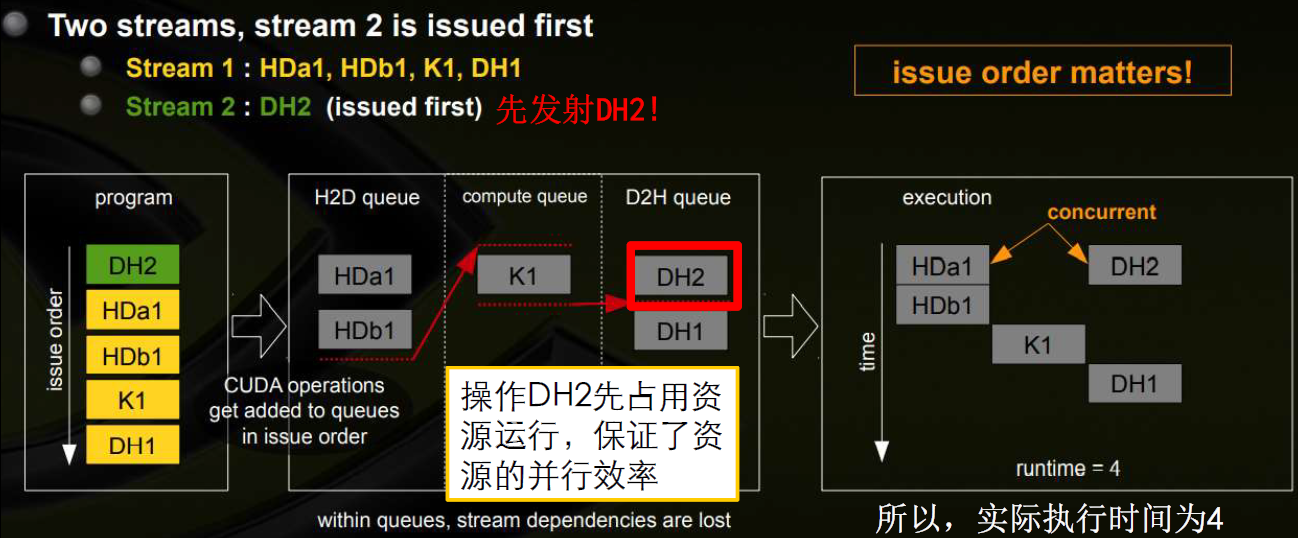
- 左边将多个流以DFS方式发射,右边将多个流以BFS方式发射
- 每个操作操作具体占用的资源大小差异对并行性也有影响

使用流隐藏延迟
在默认流中重叠主机和设备计算
- 一些cuda runtime api具有隐式同步的效果(比如
cudaMemcpy函数),会导致主机阻塞等待 - 核函数的调用是非阻塞的
用多个流重叠多个核函数的执行
- 制约加速比的因素:(假设每个CUDA流都执行相同规模的计算)
- GPU的计算资源(SM数量,每个SM最多允许的线程数量)
- 当CUDA流较少时,增加CUDA流的数量,总耗时只是略微增加,加速比线性增加,此时加速比没有饱和
- 当CUDA流的个数到达瓶颈,继续增加CUDA流的数量时,总耗时线性增加,加速比饱和
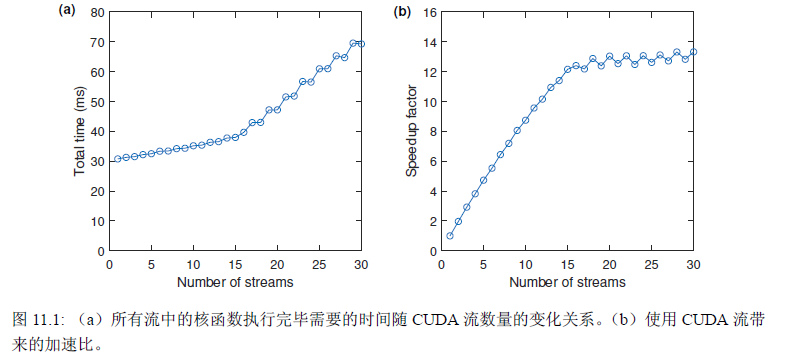
- 单个GPU中能够并发运行的核函数个数的上限
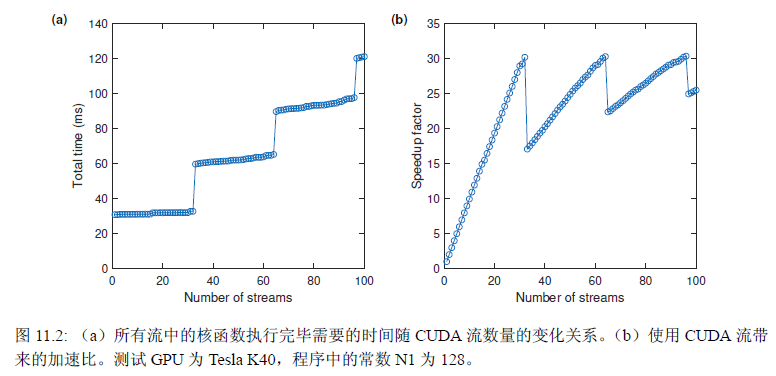
- 比如此时能够并发运行的核函数上限为32,Tesla K40有15个SM,每个SM最多允许2048个线程
- 比如此时一个核函数开1024线程,理论上最多并发运行的核函数$=\min{ \frac{15\times2048}{1024}, 32}=30$,此时限制因素为GPU的计算资源
- 比如此时一个核函数开128线程,理论上最多并发运行的核函数$=\min { \frac{15 \times 2048}{128}, 32 }=32$,此时限制因素为并发运行核函数的上限
- GPU的计算资源(SM数量,每个SM最多允许的线程数量)
- 参考
- 《CUDA编程:基础与实践》
用多个流重叠核函数的执行与数据传递
- 将数据与相应操作分成若干份,每个流中依次进行操作,形成流水线

- 理论上最大加速比为3(假设H2D,KER,D2H运行时间相同)
同步
核函数(或grid)之间的同步
- 背景:连续发射两个核函数,其调度行为未知
- 使用cuda graph显示指定核函数调度顺序(?不确定)
- 相关函数
cudaDeviceSynchronize:阻塞host端,直到所有的kernel调用完毕- 原理是device设置了
cudaDeviceScheduleBlockingSync标志,将host线程阻塞 - 在device中使用
cudaDeviceSynchronize已经被逐渐废弃
- 原理是device设置了
cudaStreamSynchornize:阻塞host端,直到流中的kernel调用完毕cudaSetDeviceFlags:记录标志,作为活动的host线程执行device代码时使用的标志cudaLaunchKernel:在CPU端使用<<<>>>launch核函数时,实际上调用的是该函数,launch核函数到GPU上执行
线程块(或Block)内部的同步
- barrier:
__syncthreads()同步Block内所有线程- 注意死锁问题:
__syncthreads必须能被块内所有线程访问到,即不要将__syncthreads放到if-else语句中
- 注意死锁问题:
__syncthreads的变种:syncthreads_xxx(int predicate)- 与
__syncthreads相同,但是有一个额外的功能: - predicate是一个条件表达式,该变种函数对所有线程评估predicate:
__syncthreads_or:如果有任意一个线程的predicate值非零,返回非零__syncthreads_and:如果对所有线程的predicate值非零,返回非零__syncthreads_count:统计所有线程中predicate值非零的线程数量
- 应用:last-block guard确定最后一个线程块(编号最后的线程块未必是最后运行结束的)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18__device__ int counter = 0; __device__ bool lastBlock(int* counter){ // 方法一: __shared__ int last; // 表示当前已经调度发射了多少个线程块 __threadfence(); // 确保之前计算的结果已经写入内存,对所有线程块可见 if(threadIdx.x == 0) // 每个块中第一个线程维护last的值 last = atomicAdd(counter, 1); // 原子更新全局内存中的变量,将更新后的值返回到共享内存中 __syncthreads(); // 块内所有线程同步,有必要。如果没有线程块内同步,则一个线程块内对last的访问有的是新值,有的是旧值,但是又必须要求一个线程块内部的last值都相同。注意没有保证不同的线程块之间是同步的 return last == gridDim.x-1; } __device__ bool lastBlock(int* counter){ // 方法二: __threadfence(); int last = 0; // 寄存器变量 if(threadIdx.x == 0) last = atomicAdd(counter, 1); // 块内线程不需要完全同步 return __syncthreads_or(last == gridDim.x-1); // 仍需要使用__syncthreads_or,因为一个线程块内部,只有0号线程的last是用来维护计数的。因此只要0号线程计算完即可确定当前线程块是否为最后一个 }
- 与
线程块(或Block)之间的同步
全局锁+原子操作
线程块内选一个代表,通过维护锁变量,代表先进行同步,从而线程块同步
| |
无锁方法
- 将块间同步转换为块内同步
- 为每个线程块分配一个同步变量,形成一个数组
Arrayin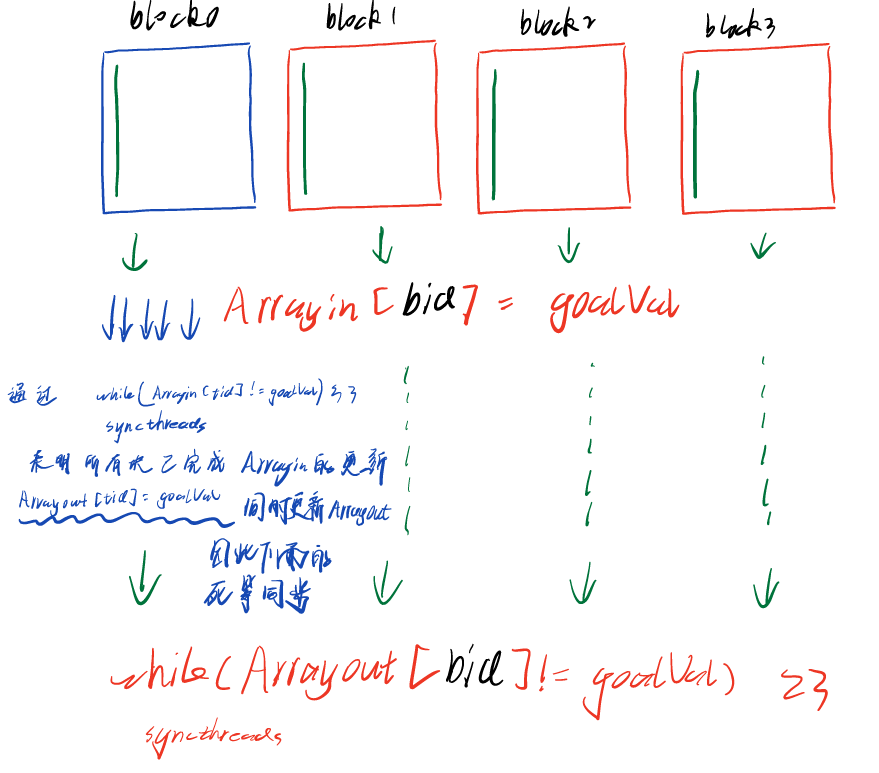
- 为每个线程块分配一个同步变量,形成一个数组
| |
内存fence
- 背景:CUDA 编程模型假定了一种弱顺序(weakly-ordered)一致性的内存模型
- 内存一致性(memory consistency):访存操作在全局中生效(或观察到的)顺序问题, 是指令集所规范的,是软硬件接口的一部分
- 缓存一致性(cache coherence):同一个地址在不同的缓存中一致性问题,是完全的硬件实现策略,程序员无关,是集成电路设计者考虑的东西。
- 内存fence:读写操作可能进行重排or优化,添加fence之后,fence之前的op一定比fence之后的op先执行。即抑制编译器重排、抑制乱序。
- 内存fence:The CUDA programming model assumes a device with a weakly-ordered memory model. Memory fence functions can be used to enforce a sequentially-consistent ordering on memory accesses.
volatile:声明一个变量,防止编译器优化,防止这个变量存入缓存,如果恰好此时被其他线程改写,那就会造成内存缓存不一致的错误,所以volatile声明的变量始终在全局内存中。
- 内存fence只会影响自己线程中内存操作的顺序,保证自己的数据fence后能够被其他线程安全的访问,并不能像
__syncthreads那样保证内存操作对于同block中的其他线程可见 - 相关函数
__threadfence_block():该函数调用后,该线程在此语句前对全局存储器或共享存储器的访问已经全部完成,且结果对block内所有线程可见。__threadfence():该函数调用后,该线程在此语句前对全局存储器或共享存储器的访问已经全部完成,且结果对grid内所有线程可见。__threadfence_system():该函数调用后,该线程在此语句前对全局存储器或共享存储器的访问已经全部完成,且结果对system(CPU+GPU)内所有线程可见。
- 参考:
warp同步
warp内(inter-warp)同步
barrier:
__syncwarps()同步一个warp中的线程线程束内函数都有
_sync后缀,表示这些函数都具有隐式的同步功能。- 线程束表决函数(warp vote functions)
unsigned __ballot_sync(unsigned mask, int predicate):如果线程束内第n个线程参与计算(旧掩码)且predicate值非零,则返回的无符号整型数(新掩码)的第n个二进制位为1,否则为0int __all_sync(unsigned mask, int predicate):线程束内所有参与线程的predicate值均非零,则返回1,否则返回0int __any_sync(unsigned mask, int predicate):线程束内所有参与线程的predicate值存在非零,则返回1, 否则返回0
- 线程束匹配函数(warp match functions)
- 线程束洗牌函数(warp shuffle functions):最后一个参数表示逻辑上的warp大小
T __shfl_sync(unsigned mask, T v, int srcLane, int w = warpSize):参与线程返回标号为 srcLane 的线程中变量 v 的值。该函数将一个线程中的数据广播到所有线程。T __shfl_up_sync(unsigned mask, T v, unsigned d, int w=warpSize):标号为t的参与线程返回标号为 t-d 的线程中变量v的值,t-d<0的线程返回t线程的变量v。该函数是一种将数据向上平移的操作,即将低线程号的值平移到高线程号。- 例如当w=8、d=2时,2-7号线程将返回 0-5号线程中变量v的值;0-1号线程返回自己的 v。
T __shfl_down_sync(unsigned mask, T v, unsigned d, int w=warpSize):标号为t的参与线程返回标号为 t+d 的线程中变量v的值,t+d>w的线程返回t线程的变量v。该函数是一种将数据向下平移的操作,即将高线程号的值平移到低线程号。
- 例如当w=8、d=2时,0-5号线程将返回2-7号线程中变量v的值,6-7号线程将返回自己的 v。
T __shfl__xor_sync(unsigned mask, T v, int laneMask, int w=warpSize):标号为t的参与线程返回标号为 t^laneMask 的线程中变量 v 的值。该函数让线程束内的线程两两交换数据。
- 线程束矩阵函数(warp matrix functions)
- 线程束表决函数(warp vote functions)
例子:使用warp shuffle函数进行规约:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22void __global__ reduce_shfl(const real *d_x, real *d_y, const int N){ const int tid = threadIdx.x; // tid从0到blockDim.x const int bid = blockIdx.x; const int n = tid + bid * blockDim.x; extern __shared__ real s[]; // 比如大小128 s[tid] = (n < N) ? d_x[n] : 0.0; const unsigned FULL_MASK = 0xffffffff; __syncthreads(); // 线程块同步函数 for(int offset = blockDim.x >> 1; offset >= 32; offset >>= 1){ if(tid < offset) s[tid] += s[tid + offset]; __syncthreads(); } real y = s[tid]; for(int offset = 16; offset > 0; offset >>= 1) y += __shfl_down_sync(FULL_MASK, y, offset); // 线程tid返回线程tid+offset中寄存器变量y的值 if(tid == 0) atomicAdd(d_y, y); }
协作组
协作组(cooperative groups):提供了线程块以上级别的同步
thread_group- 协作组编程模型中最基本的类型,是线程块级别的协作组
- 成员函数:
void sync(),同步组内所有线程;(相当于__syncthreads函数)unsigned size(),返回组内总的线程数目,即组的大小;unsigned thread_rank(),返回当前调用该函数的线程在组内的标号(从0计数)bool is_valid(),如果定义的组违反了任何cuda限制,返回 false,否则true
thread_block继承于thread_group_base<T>,thread_group_base<T>继承于thread_groupdim3 group_index(),返回当前调用该函数的线程的线程块指标,等价于blockIdx;dim3 thread_index(),返回当前调用该函数的线程的线程指标,等价于threadIdx;this_thread_block():初始化一个thread_block对象tiled_partition():将一个thread_block划分为若干片(tile),每片构成一个thread_group
1 2 3 4 5 6 7#include <cooperative_groups.h> using namespace cooperative_groups; // 相关变量和函数定义在该命名空间下 // namespace cg = cooperative_groups; // 取别名 thread_block g = this_thread_block(); // g相当于一个之前的线程块,这里将其包装为一个类型 thread_group myWarp = tiled_partition(g, 32); // 将thread_block划分为thread_group thread_group g4 = tiled_partition(myWarp, 4); // 可以将thread_group进一步细分thread_block_tile- 使用模板,在编译期划分 线程块片(thread block tile)
1 2thread_block_tile<32> g32 = tiled_partition<32>(this_thread_block()); thread_block_tile<32> g4 = tiled_partition<4>(this_thread_block());
- 使用模板,在编译期划分 线程块片(thread block tile)
线程块片具有额外的函数(类似线程束内函数):
unsigned ballot(int predicate);int all(int predicate);int any(int predicate);T shfl(T v, int srcLane);T shfl_up(T v, unsigned d);T shfl_down(T v, unsigned d);T shfl_xor(T v, unsigned d);
- 与一般的线程束不同,线程组内的所有线程都要参与代码运行计算;同时,线程组内函数不需要指定宽度,因为该宽度就是线程块片的大小。
例子:使用协作组进行规约:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23void __global__ reduce_cp(const real *d_x, real *d_y, const int N){ const int tid = threadIdx.x; // tid从0到blockDim.x const int bid = blockIdx.x; const int n = tid + bid * blockDim.x; extern __shared__ real s[]; // 比如大小128 s[tid] = (n < N) ? d_x[n] : 0.0; __syncthreads(); // 线程块同步函数 for(int offset = blockDim.x >> 1; offset >= 32; offset >>= 1){ if(tid < offset) s[tid] += s[tid + offset]; __syncthreads(); } real y = s[tid]; thread_block_tile<32> g = tiled_patition<32>(this_thread_block()); for(int i = g.size() >> 1; i > 0; i >>= 1) y += g.shfl_down(y, i); // 使用协作组的成员函数与使用warp shuffle函数具有等价的执行效率 if(tid == 0) atomicAdd(d_y, y); }more
原子操作
- 两类原子函数:
- atomicAdd_system:将原子函数的作用范围拓展到所有节点(host和device)
- atomicAdd_block:将原子函数的作用范围缩小至一个线程块
- 一个特殊的原子函数:
atomicCAS,所有其他原子函数都可以使用它来实现
- 相关语法:
- 原子函数的返回值都是原来的旧值
- 原子函数都是
__device__函数,只能在核函数中使用 - 原子函数操作的地址可以位于全局内存,也可以位于共享内存
- 原子操作开销与是否存在竞争相关,且参与竞争者越少,开销越小
- 例子:使用原子函数进行规约
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16void __global__ reduce_shared(real *d_x, real *d_y, const int N){ const int tid = threadIdx.x; const int bid = blockIdx.x; const int n = blockIdx.x * blockDim.x + threadIdx.x; extern __shared__ real s_y[]; // 动态共享内存 s_y[tid] = (n < N) ? d_x[n] : 0.0; // 将全局内存中的数据拷贝到线程块对应的共享内存中 __syncthreads(); // 保证一个线程块中的同步,但是不能保证不同线程块之间的同步 for(int offset = blockDim.x >> 1; offset > 0; offset >>= 1){ if(tid < offset) s_y[tid] += s_y[tid + offset]; __syncthreads(); } if(tid == 0) atomicAdd(&d_y[0], s_y[0]); // 使用原子操作,将结果累加到d_y[0] }