编程模型
线程组织层次
grid 网格
由一个内核函数启动所产生的所有线程统称为一个网格(grid)
grid size和block size都是三维结构,
dim3类型数据类型
dim3是基于uint3定义的:- 比如在主机端配置核函数grid size和block size时,数据类型为
dim3类型,此时变量可以进行修改 - 比如核函数在运行时,在设备端查询grid size和block size时,此时数据类型为
uint3,此时变量已经固定无法修改
- 三维网格
grid_size(gridDim.x, gridDim.y, gridDim.z) - 三维线程块
block_size(blockDim.x, blockDim.y, blockDim.z)
- 比如在主机端配置核函数grid size和block size时,数据类型为
thread block 线程块
- 一个grid可以分为很多个thread block,由
blockIdx定位 - 线程块大小(block size,每个block中线程数量)为1024
- 一个grid可以分为很多个thread block,由
warp(thread)
- 一个thread block中包含很多thread,每相邻的32个(warpSize)thread组成一个warp
- 每个thread可以由线程块id
blockIdx和线程idthreadIdx唯一确定,同样也是三维结构
函数
核函数
核函数配置:
<<<grid_size, block_size, shared_memory_size, stream>>>核函数的启动都是异步的,host只是启动(或launch)核函数
- 可以使用
cudaDeviceSynchronize进行显式同步,或者进行隐式同步
- 可以使用
核函数的语法相关:
- 返回类型必须是
void - 必须使用限定符
__glolbal__,也可以加上 c++ 限定符(比如static); - 核函数支持 c++ 的重载机制;
- 核函数不支持可变数量的参数列表,即参数个数必须确定;
- 一般情况下,传给核函数的数组(指针)必须指向设备内存(“统一内存编程机制”除外);
- 核函数不可成为一个类的成员(一般以包装函数调用核函数,将包装函数定义为类成员);
- 在计算能力3.5之前,核函数之间不能相互调用;之后,通过“动态并行”机制可以调用;
- 返回类型必须是
有时启动的线程数量多于数组元素个数,因此通常使用if语句进行控制
设备函数
核函数可以调用不带执行配置的自定义函数,即设备函数。
函数执行空间标识符(函数类型限定符):确定一个函数在哪里被调用,在哪里被运行:
区分变量类型限定符:
__device__全局内存,__shared__共享内存,__constant__常量内存,__managed__统一内存__global__修饰的函数称为核函数,一般由主机调用、在设备中执行;__device__修饰的函数称为设备函数,只能被核函数或其他设备函数调用、在设备中执行;__host__修饰主机端的普通 c++ 函数,在主机中被调用、在主机中执行,一般可以省略;
相关语法:
- 设备函数可以有返回值
- 不能同时用
__global__和__device__修饰函数(即一个函数不能同时是核函数和设备函数) - 不能同时用
__global__和__host__修饰函数(即一个函数不能同时是核函数和主机函数) - 可以同时用
__host__和__device__修饰函数,从而减少代码冗余,此时编译器将分别在主机和设备上编译该函数,生成两份不同的机器码 - 可以通过
__noinline__建议编译器不要将一个设备函数当作内联函数; - 可以通过
__forceinline__建议编译器将一个设备函数当作内联函数。
内存模型
执行模型
并行方式
- 指令级并行:如果某个warp中两条指令相互独立,则可以依次发射,进行指令级并行
- 线程并行方式:SIMT
- SIMD:比如向量运算指令
- 一个线程可以同时处理多个数据,但是当前只使用一个ALU。比如使用ARM指令拓展NEON中的向量加指令,可以同时进行四个int的相加
- 多个数据使用使用相同的指令一起执行
- SIMT
- 从硬件上看,所有的core有各自的执行单元(与SIMD共用一个ALU不同)
- 从软件上看,每个线程都有自己的指令计数器、寄存器,因此每个线程可以有自己独立的执行路径
- 尽管一个warp中的所有线程在相同的程序地址上同时开始执行,但是单独的线程仍然可能有不同的行为
- SIMD:比如向量运算指令
- warp并行方式:SM上同一个线程块的多个warp,通过大量的core实现并行,通过调度和流水线实现并发和并行
执行模型
host启动核函数,GPU异步执行
GPU根据运行配置,GPU将启动的核函数作为一个grid,并划分为线程块
- 一个线程块分配到一个SM执行,多个线程块可以分配到同一个SM执行,但是一个线程块无法分配到多个SM
线程块划分为warp
由于资源和硬件限制,并非所有的warp都可以同时执行,因此warp可以分类:
资源和硬件限制:
限制了运行的warp的最大数量
SM限制:每个SM、每个block的最大共享内存大小
寄存器限制:每个SM、每个block、每个thread的最大寄存器数量
每个SM中resident block、resident warps、resident threads的最大数量
寄存器和共享内存都是以256个或字节为单元进行分配的
限制了每个时钟周期发射的warp的数量:比如一个warp scheduler如果只有一个issue slot,则只能从warp slots中发生一个warp
- active warp:进入到warp slots中的warp(另一种说法是,当寄存器和共享内存分配给线程块,该线程块内的warp处于活跃状态)
- stalled warp:阻塞的warp
- 造成阻塞的情况:正在取指,依赖内存指令的访存结果,依赖于之前指令的执行结果,pipeline正在忙,同步barrier
- eligible warp:符合条件的warp(32个cuda core可用于执行,数据已经就绪),可以运行的warp
- selected warp:选定的warp,当前正在运行的warp
- stalled warp:阻塞的warp
- inactivate warp
由于计算资源是在warp之间分配的,且warp的整个生命周期都在片上(上下文常驻SM),所以warp的上下文切换是非常快速的
- 而CPU中寄存器数量很有限,进行需要保护和切换上下文
参考
隐藏延迟:如果warp scheduler在指令周期的每个时钟周期都有一些可以发射的指令,则最大化硬件利用率。通过流水线,来隐藏延迟
- 同一个线程中的指令使用流水线来进行指令级并行
- 两类指令:
- 算数指令:使用ALU,延迟小(大约10~20个时钟周期)
算数指令隐藏延迟的目的是使用全部的计算资源
算数运算的并行可以表示为:隐藏算数指令延迟所需要的操作数量
- 所需的指令数量=延迟 $\times$ 吞吐量/32
- 吞吐量是每个SM每个时钟周期的操作数量,由于SIMT,一个指令对应32个线程的操作,因此指令的吞吐量=(操作数量)吞吐量/32
理论上所需active的warp数量=延迟 $\times$ 吞吐量/32,还是延迟$\times$ warp_scheduler数量,不是很清楚
比如有4个warp scheduler,一个算数指令的耗时或延迟是8个周期,则为了完全隐藏延迟,最少需要32个active的warp;如果warp表现出指令并行性,则需要的active的warp数量更少
- 内存指令:使用LD/ST,延迟较大(大约400~800个时钟周期)
- 内存指令隐藏延迟的目的是使用全部的带宽
- 内存操作的并行可以表示为:每个周期内隐藏内存延迟所需的字节数
- $$所需active的warp数量=\frac{\frac{访存延迟(周期)}{内存频率(周期/s)} \times 带宽(GB/s)}{每个线程访问的数据量(B) \times 32} $$
- 辨析:
- 传统CPU流水线:每个硬件部件(译码单元,ALU等)当前运行的,属于不同的指令,隐藏的是整个指令从取指到写回的整个过程。独立的算数指令的流水线也与此类似。
- CPU通过cache来隐藏延迟,而GPU通过计算来隐藏延迟
- 算数指令的流水线:在一个SM中,warp之间运行的是不同的指令,因为GPU指令相对CPU而言较慢,所以隐藏的是GPU指令的运行时间
- 内存指令的流水线:若干个SM中的所有core,使用流水线,从而隐藏访存延迟
- 内存延迟的时候,计算资源core正在被别的warp使用,这两种延迟使用的是不同的硬件资源,但是遵循相同的原理
- 传统CPU流水线:每个硬件部件(译码单元,ALU等)当前运行的,属于不同的指令,隐藏的是整个指令从取指到写回的整个过程。独立的算数指令的流水线也与此类似。
- 算数指令:使用ALU,延迟小(大约10~20个时钟周期)
- 一方面,隐藏延迟需要足够多的活跃的warp,数量越多,隐藏越好;另一方面,warp的数量又受到资源和硬件的限制,不能过多
warp占用率:CUDA Occupancy Calculator
- warp占用率=$\frac{SM中活跃的warp的数量}{SM最大支持warp数量}$
- nvcc编译时,添加编译选项
--ptxas-options=-v,可以统计共享内存和寄存器的使用量
- nvcc编译时,添加编译选项
- 高占用率不一定有高性能,但是低占用率不利于隐藏延迟
- 占用率限制因素:
- 资源限制:共享内存和寄存器限制
- 硬件设计限制:每个SM的最多block数、warp数、thread数
- 权衡
- 如果每个线程块中线程太少,线程块数量变多,容易受到每个SM中最多block数的限制,导致占用率低
- 如果每个线程块中线程太多,每个线程块中warp数量变多,线程块数量减少,容易受到每个线程寄存器/共享内存的限制,剩余的一些warp没法组成一个线程块,导致占用率变低
- 参考
- https://blog.csdn.net/weixin_44444450/article/details/118058031
- 一个占用率计算例子:https://blog.csdn.net/wd1603926823/article/details/108871290
- https://face2ai.com/CUDA-F-3-2-%E7%90%86%E8%A7%A3%E7%BA%BF%E7%A8%8B%E6%9D%9F%E6%89%A7%E8%A1%8C%E7%9A%84%E6%9C%AC%E8%B4%A8-P2/
- warp占用率=$\frac{SM中活跃的warp的数量}{SM最大支持warp数量}$
避免分支
一个warp中的if语句如果在运行时判断产生分支,会导致一个warp中对应的线程依次执行相应路径,其他线程等待(或是假运行),相当于每个代码块都跑了一遍,分支数量越多,性能越差
- 如果if中没有产生分支,则不用考虑
- 比如for循环中包含了if判断,则很可能
- 可以将分支粒度调整为warp大小的倍数,使得一个warp中执行同一个路径,不同warp间可以执行不同路径,比如
(tid/warpSize)%2进行奇偶交错
独立线程调度机制中,每个线程有自己的程序计数器和寄存器,此时SIMT如何运行?不是很清楚
metric:不是很清楚
- Branch Efficiency is a measure of how many branches diverged. 100% means no branches diverged. When a branch diverges the warp thread active mask is reduce to be less than 32 so the execution is not as efficient. In addition the branch may have to be executed multiple times based upon the number of ways the branch diverged.
- Control Flow Efficiency is a measure of how many threads in a warp were active for each instruction. Unless you launch a non-multiple of 32 threads this will be 32 threads or 100%. This number will be less than 100% if the code diverges.
参考
循环展开
循环展开:在一次循环中,完成多次循环的任务,从而减少循环的迭代次数
- 减少了循环判断次数(减少指令消耗)
- 循环内部可以有更多独立的操作,有利于流水线
例子:reduce中循环展开
- 首先一个线程累加多个数据:shrink
- 收益:线程数量减半(指数减少)
- 代价:多了一次(或若干次)访存,但是可以使用流水线隐藏延迟
- 然后折半reduce的过程
- 要求此时数组长度必须为2的幂次,因此可以写成模板、在编译期判断
- 最后是一个warp中的reduce过程:此时计算的线程数量<=32,
- 不仅没有了循环判断,而且读写过程可以充分使用流水线
- 首先一个线程累加多个数据:shrink
动态并行
优点:
- 让复杂的kernel变得有层次,比如实现递归核函数
- 可以等到执行的时候再创建执行配置,利用GPU硬件调度器和加载平衡器动态的调整以适应数据驱动或工作的负载
缺点:
- 运行效率更低
过程
- 子grid被父thread启动,必须在对应的父thread,父thread block,父grid结束之前结束。所有的子grid结束后,父thread,父thread block,父grid才能结束
- 如果父thread调用子grid时没有显式同步,则运行时保证,父thread与子grid隐式同步
- 需要仔细考虑内存竞争的问题
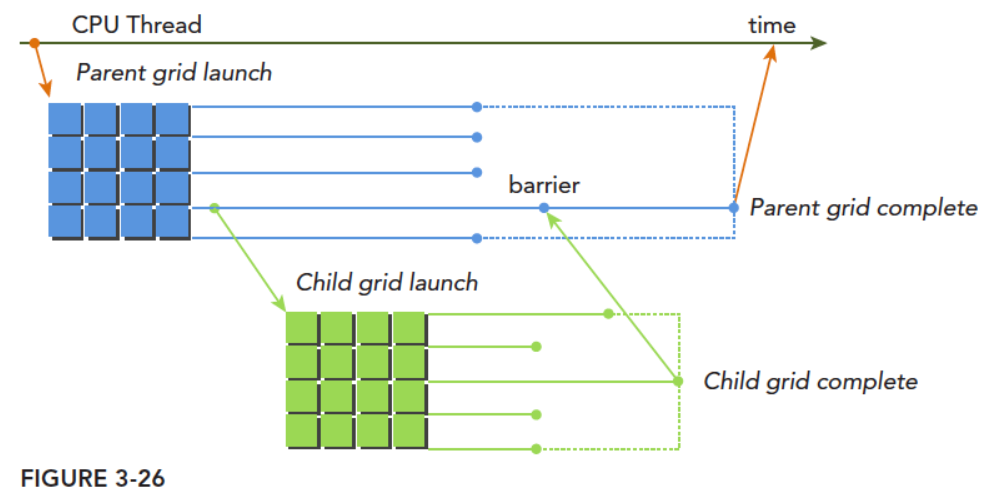
编译时需要加上
-lcudadevrt --relocatable-device-code true--relocatable-device-code true表示生成可重新定位的代码