CUDA编译链和兼容性
兼容性
CPU与GPU的区别
- CPU只有少量的计算核心,有更多晶体管用于数据缓存和流程控制,
- GPU有大量计算能力较弱的计算核心,用于控制和缓存的晶体管较少
GPU系列:
- Tesla系列:使用ECC内存,用于科学计算。后来也叫Data Center GPUs。
- Quadro系列:专业级,用于OpenGL、CAD等需要高精度计算的场景。后来也叫Workstation GPUs。
- GeForce系列:消费级,用于游戏和计算,但是没有ECC
- Tegra系列:移动处理器
- Jetson系列:嵌入式
GPU架构、计算能力与对应系列
- 计算能力(Compute Capability)决定了GPU硬件支持的功能,反映了设备支持的指令集及其他规范,也称SM version,注意GPU计算能力不等价于计算性能
架构 计算能力Compute Capability 发布时间 Tesla系列 Quadro系列 GeForce系列 Jetson系列 Tesla X = 1 2006 Fermi X = 2 2010 Kepler X = 3 2012 Kepler K系列 Quadro K系列 GeForce 600/700系列 Tegra K1 Maxwell X = 5 2014 Maxwell M系列 Quadro M系列 GeForce 900系列 Tegra X1 Pascal X = 6 2016 Pascal P系列 Quadro P系列 GeForce 10系列 Tegra X2 Volta X = 7 2017 Tesla V系列 - TITAN V AGX Xavier Turing X.Y = 7.5 2018 Tesla T系列 Quadro RTX系列 GeForce 16系列,GeForce 20系列 AGX Xavier Ampere X = 8 2020 Tesla A系列 RTX A系列 GeForce 30系列 Ada Lovelace X.Y = 8.9 2022 L4、L40 RTX Ada系列 GeForce 40系列 Hopper X = 9 2022 H100 -
- 计算能力(Compute Capability)决定了GPU硬件支持的功能,反映了设备支持的指令集及其他规范,也称SM version,注意GPU计算能力不等价于计算性能
CUDA开发平台
- CUDA 提供两个编程接口
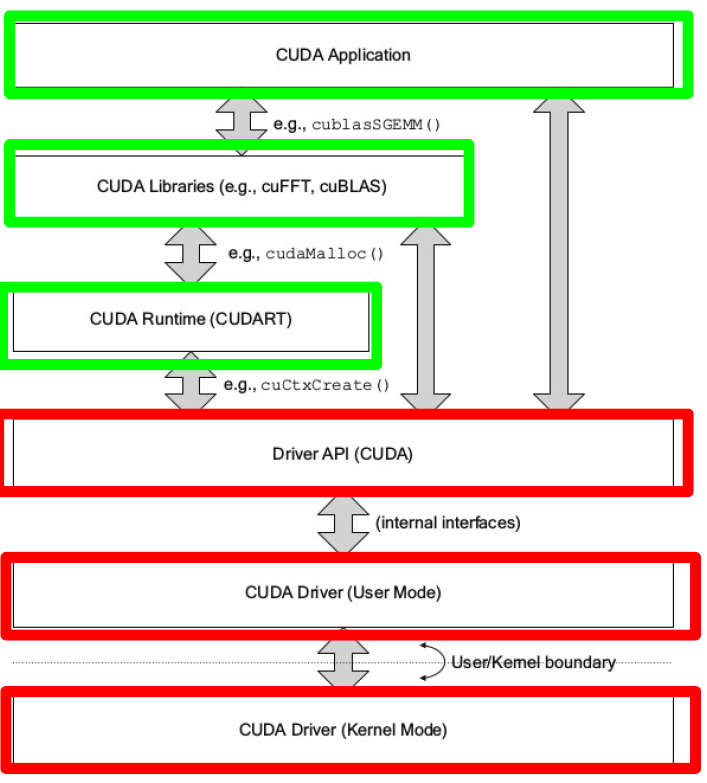
- CUDA driver API:low-level
- CUDA (driver) library由NVIDIA driver安装,比如常用的共享库
libcuda.so,对应头文件为cuda.h,里面提供的API称为CUDA driver API- 同时可以看到NVIDIA driver的版本:
find / -name libcuda.*
- 同时可以看到NVIDIA driver的版本:
- NVIDIA driver同时包含了
nvidia-smi命令,可以看到NVIDIA driver的版本,以及当前NVIDIA driver支持的最高CUDA版本(向下兼容) - 或者使用函数
cudaDriverGetVersion(int* driverVersion)
- CUDA (driver) library由NVIDIA driver安装,比如常用的共享库
- CUDA runtime API:high-level
- CUDA Runtime library由CUDA Toolkit安装,比如常用的共享库
libcudart.so,对应头文件为cuda_runtime.h,里面提供的API称为CUDA runtime APIcuda_runtime_api.h是纯C版本,cuda_runtime.h是C++版本- 离线安装的CUDA工具包会默认携带与之匹配特定的驱动程序
- CUDA Toolkit中同时包含了一些工具比如编译器nvcc,
nvcc -V显示的CUDA版本是runtime API版本- cuda driver API版本(即驱动支持的最高cuda版本)应该高于cuda runtime API版本(即当前安装的cuda toolkit版本)
- 或者使用函数
cudaRuntimeGetVersion(int *runtimeVersion)
- CUDA Runtime library由CUDA Toolkit安装,比如常用的共享库
- CUDA driver API:low-level
- 注意不要将GPU计算能力与CUDA (driver/runtime)版本混淆
- 参考
编译相关
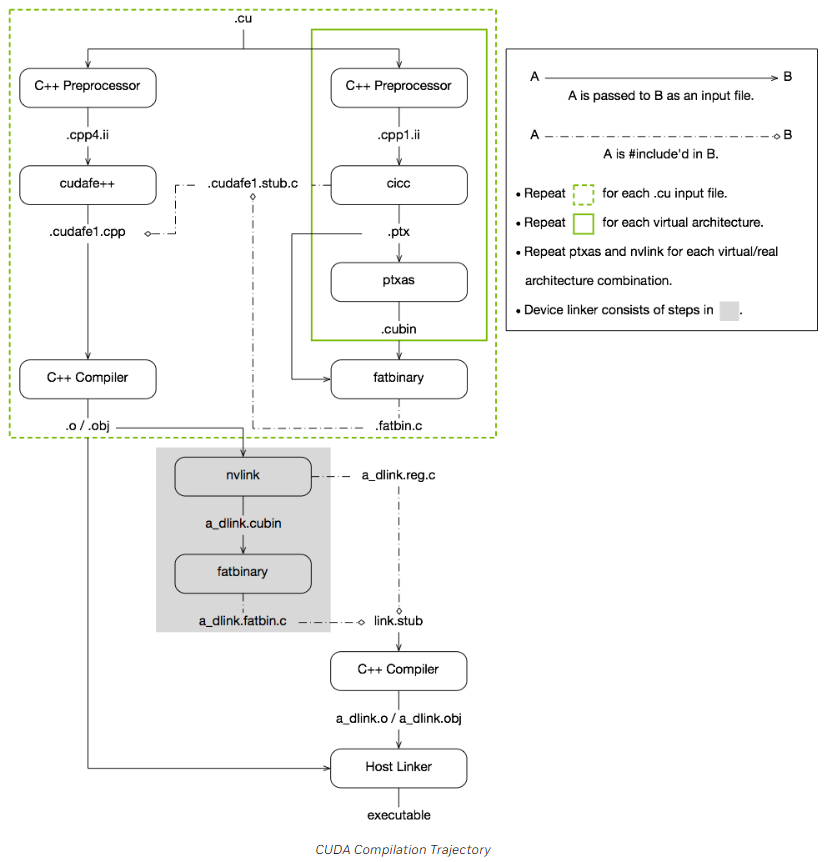
编译过程
- 编译device code
- 首先将预处理之后的C++ code经过CICC compiler编译成PTX code
- PTX可以视为虚架构的汇编,虚架构体现了应用程序对GPU计算能力的要求,版本尽量低,因此可以适用于更加广泛的GPU架构
- 再使用ptxas (PTX optimizing assembler),根据实架构,将PTX code编译成cubin二进制机器码
- .cubin:CUDA device code binary file (CUBIN) for a single GPU architecture
- 将PTX code和cubin放到fatbin.c文件中
- .fatbin:CUDA fat binary file that may contain multiple PTX and CUBIN files
- 首先将预处理之后的C++ code经过CICC compiler编译成PTX code
- 编译host code
- 将预处理之后的C++ code,使用cudafe++将host和device部分分离
- 分离后的host代码,结合device code部分得到的fatbin.c文件,进行编译
- 在host code看来,device code其实就是一段数据。
- 对每一个.cu文件都执行单独的host code和device code编译
- 链接:
- 使用nvlink将所有.o目标文件中的device code重新链接到一个cubin文件中,并通过fatbinary转换为.fatbin.c文件
- 将.fatbin.c文件,结合一些其他的文件,编译得到device code最终对应的目标文件
- 将host code的目标文件和device code最终的目标文件链接起来,得到最终的可执行文件
- 编译device code
使用
需要选项
-arch=compute_XY指定一个PTX虚拟架构的计算能力,虚架构版本:Virtual Architecture Feature ListArchitecture 虚架构 实架构 Maxwell compute_50,compute_52,compute_53sm_50,sm_52,sm_53Pascal compute_60,compute_61,compute_62sm_60,sm_61,sm_62Volta compute_70,compute_72sm_70,sm_72Turing compute_75sm_75Ampere compute_80,compute_86,compute_87sm_80,sm_86,sm_87Ada Lovelace compute_89sm_89Hopper compute_90,compute_90asm_90,sm_90a需要选项
-code=sm_ZW指定一个真实架构的计算能力,实架构版本:GPU Feature List- CUDA二进制兼容性只能保证局限在相同大版本计算能力的架构中
- 实架构的计算能力必须大于等于虚架构的计算能力
如果希望编译出来的文件能在更多的GPU上运行,可以使用
-gencode同时指定多组计算能力,生成多个PTX版本代码,例如:1 2 3-gencode arch=compute_35, code=sm_35 -gencode arch=compute_50, code=sm_50 -gencode arch=compute_60, code=sm_60- 此时,编译出来的可执行文件将包含3个二进制版本,在不同架构的GPU中运行时会自动选择对应的二进制版本
-code=可以指定虚架构,此时将进行即时编译,只会包含PTX代码
如果在运行期间找不到当前架构的二进制版本代码,则使用即时编译
- 即时编译推迟cubin的生成,将PTX代码在runtime内编译成cubin然后执行,因为runtime时已经知道当前运行在哪种GPU架构中,因此可以直接生成
- 缺点是增加了程序的启动延迟,但是可以使用编译缓存来缓解
默认cuda以whole program compilation mode来编译
reference and more reading
nvcc编译选项
-g:在host端生成调试信息-G:在device端生成调试信息。如果-dopt未指定,则关闭编译优化。-lineinfo:为device端生成行号,同时将source information嵌入到可执行文件中-dopt:如果-G没有指定,则-dopt=on,允许device端代码编译优化。如果-G指定,enables limited debug information generation for optimized device code
常用编译命令:
nvcc -lineinfo -arch=compute_86 -code=sm_86- 或者
alias mynvcc='nvcc -lineinfo -arch=compute_86 -code=sm_86'
- 或者
架构发展
Overview


Tesla
G80
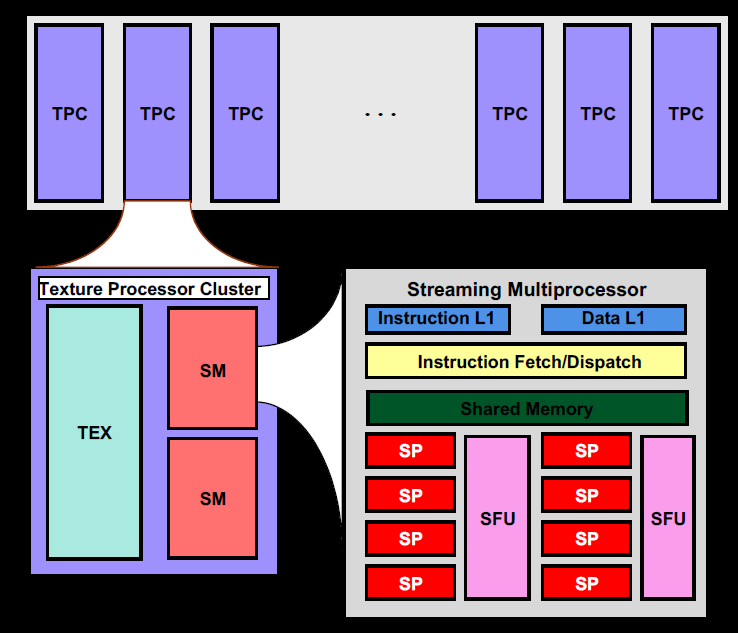
- SP(Streaming Processor):scalar ALU for a single CUDA thread
- ALU执行是流水线化的,即一项操作会被分为X个步骤由X个组件去处理,每个步骤都耗费1周期。虽然一条指令要X周期才能执行完,但对于每个组件只要1周期就执行完了,所以每个周期都能送入一份数据进ALU。
- SP的频率是调度单元(以及外部纹理单元等)的2倍,所以在调度单元看来,是需要2周期去消化1条指令。
- ALU执行是流水线化的,即一项操作会被分为X个步骤由X个组件去处理,每个步骤都耗费1周期。虽然一条指令要X周期才能执行完,但对于每个组件只要1周期就执行完了,所以每个周期都能送入一份数据进ALU。
- SM(Streaming Mulitprocessor):每个线程块分配到一个SM上
- SM的频率是GPU频率的两倍
scoreboarding
作用:在指令发射阶段,检查待发射的指令是否与正在执行但尚未写回寄存器的指令之间存在数据相关。三种数据相关:
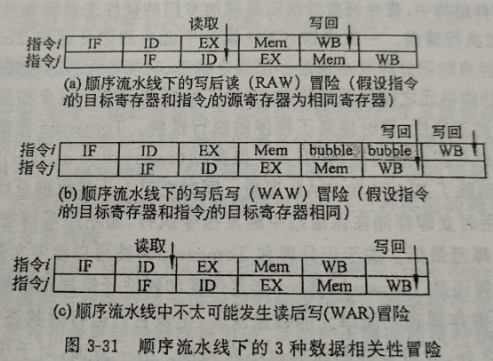
大致原理:scoreboard为每个warp寄存器分配一个bit来记录相应寄存器的写完成状态,
- 如果后序指令不存在数据相关,则进入流水线
- 如果存在数据相关,通过检查标识位,后续指令就会stall而无法发射,此时可以切换其他warp的指令进行调度
参考
- # ILP——指令级并行2:记分牌(Scoreboard)技术
- 通用图形处理器设计3.5
Fermi
以GF100为例,架构:
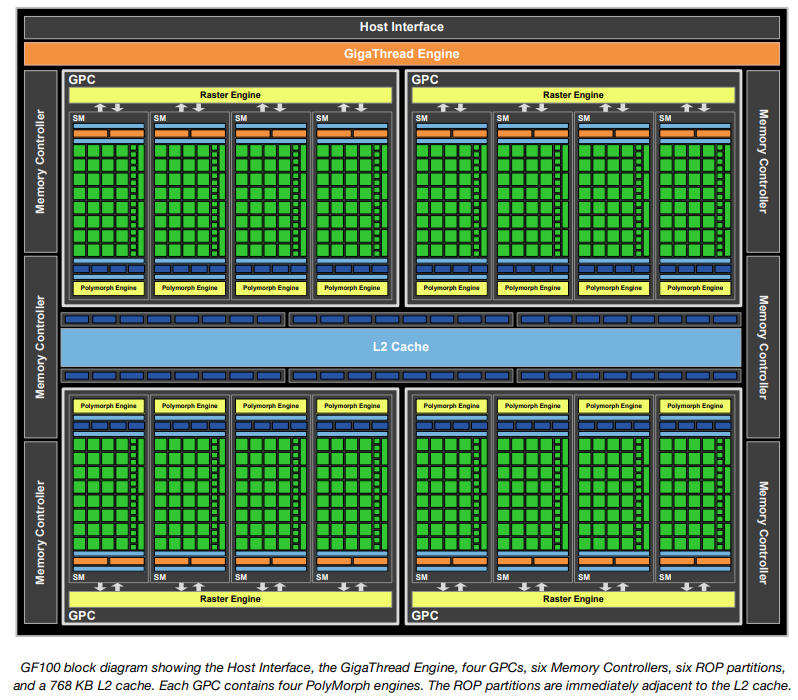
特点
- 第三代流式多处理器(SM)
- 每个SM有32个CUDA核心,比GT200多4倍
- 双精度浮点峰值性能比GT200提高8倍
- 两个warp调度器,可以同时调度和分发指令给两个独立的warp
- 64KB RAM,可供共享内存和L1缓存配置化划分使用
- 第二代并行线程执行ISA(Instruction Set Architecture指令集架构)
- 统一地址空间,完全支持C++(比如虚函数、new/delete等)
- 针对OpenCL和DirectCompute进行了优化
- 完全支持IEEE 754-2008 32位和64位精度
- 具有64位扩展的完整32位整数路径
- 内存访问指令支持向64位寻址的过渡
- 通过预测提高性能
- Predication enables short conditional code segments to execute efficiently with no branch instruction overhead
- 改进的内存子系统
- 具有可配置L1和统一L2高速缓存的NVIDIA Parallel DataCacheTM层次结构
- 之前Tesla架构没有L1、L2 cache
- 支持ECC内存的第一款GPU
- 大大提高原子内存操作性能
- 具有可配置L1和统一L2高速缓存的NVIDIA Parallel DataCacheTM层次结构
- NVIDIA GigaThread引擎
- 应用程序上下文切换速度提高了10倍
- 并发内核执行
- 无序线程块执行
- 双向可重叠的内存传输引擎
SM
SM架构:有4个执行端口
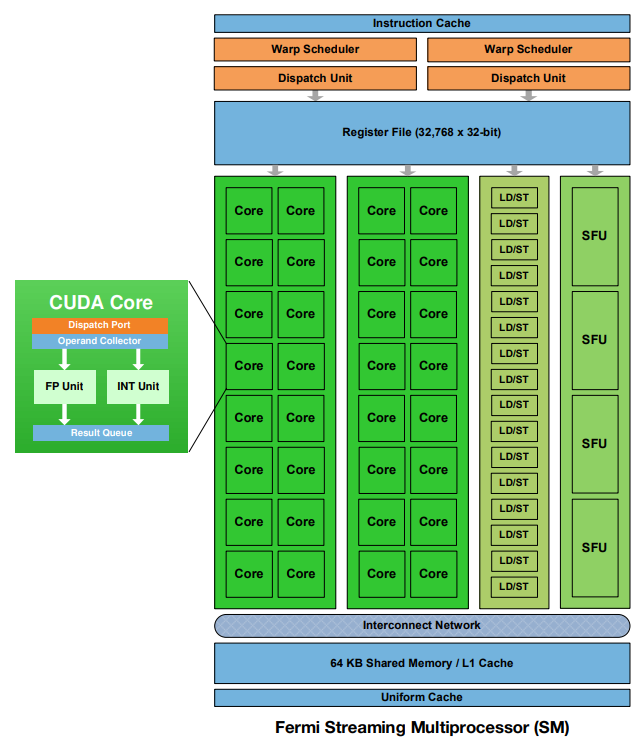
- core
- 每个CUDA处理器都有完全流水线化的整数算术逻辑单元(ALU)和浮点单位(FPU)
- LD/ST单元
- 每个SM有16个Load/Store单元,允许16个线程每个时钟周期计算源和目的地址,支持将每个地址的数据读取和存储到缓存或DRAM中
- SFU
- core
dual warp scheduler
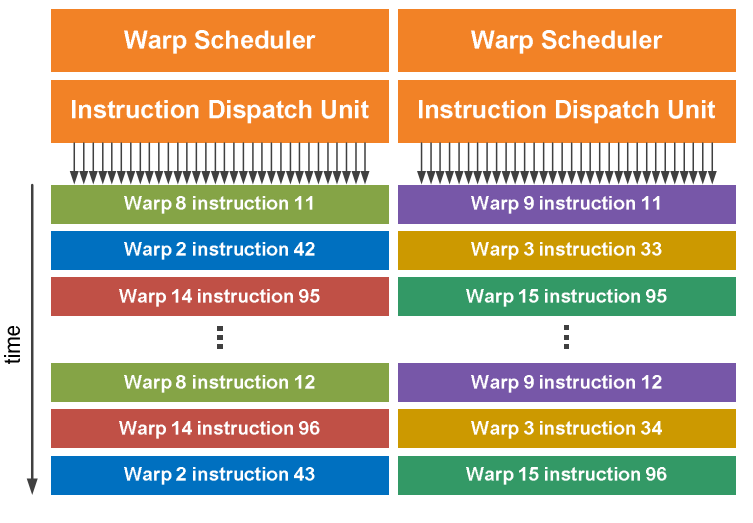
- 每个SM有两个warp scheduler和两个instruction dispatch unit,每个周期可以同时issue和execute两个warp
- warp scheduler:选择warp
- Instruction Dispatch Unit:将指令发送到对应的端口(16个core、或16个LD/ST、或4个SFU中)
- 由于SP(或者core)的频率是调度单元的2倍,因此调度单元一个周期选择一个warp,一个周期内2倍频率的core连续两次在half-warp上执行
- 由于SFU只有4个,因此一个warp在SFU中计算需要消耗8个周期,但是此时它不阻塞调度
- 由于warp之间独立运行,因此warp scheduler不需要检查指令流中的依赖关系
- 大多数指令可以这样同时dual issue,两个整数指令、两个浮点指令或混合发出整数、浮点、加载、存储和 SFU 指令;但是双精度指令不支持dual dispatch with any other operation
- 每个SM有两个warp scheduler和两个instruction dispatch unit,每个周期可以同时issue和execute两个warp
G80/GT200/Fermi对比
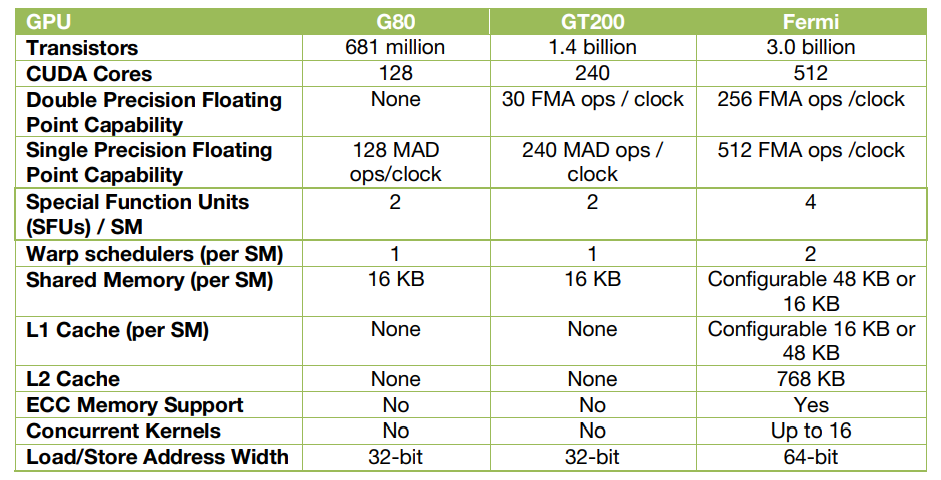
ISA
- Fermi是第一个支持PTX2.0的架构
- PTX2.0统一了各种内存空间的寻址
GigaThread
- 两级thread scheduler
- thread scheduler:将线程块调度和分配到SM,GigaThread
- warp scheduler:将warp调度和分配到执行单元
- 特点:
- 应用程序上下文切换速度更快
- concurrent(并发) kernel执行:(感觉下面的图画得有些confused?)
- 同一应用程序上下文的不同kernel可以并行在GPU上执行
- 不同应用程序上下文的kernel可以顺序执行
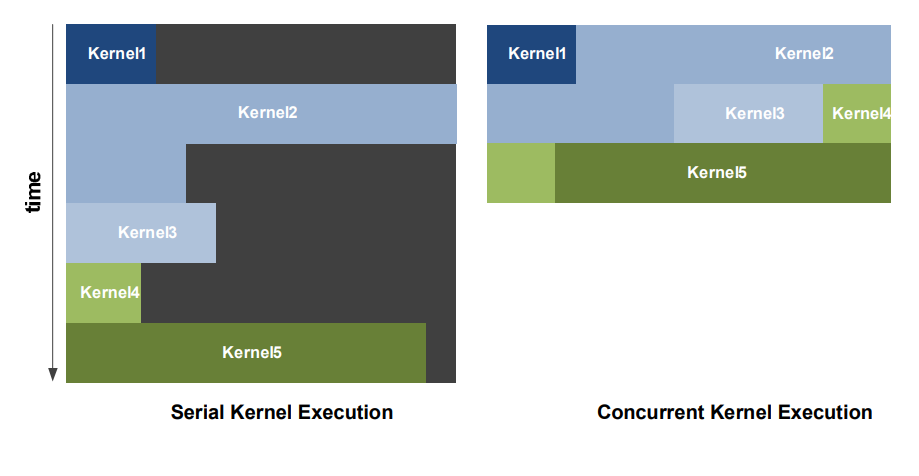
Kepler
GK110/210是Kepler架构中高端型号,用于科学计算,因此主要以这两种型号为基础来介绍kepler架构。总体架构:15个SMX
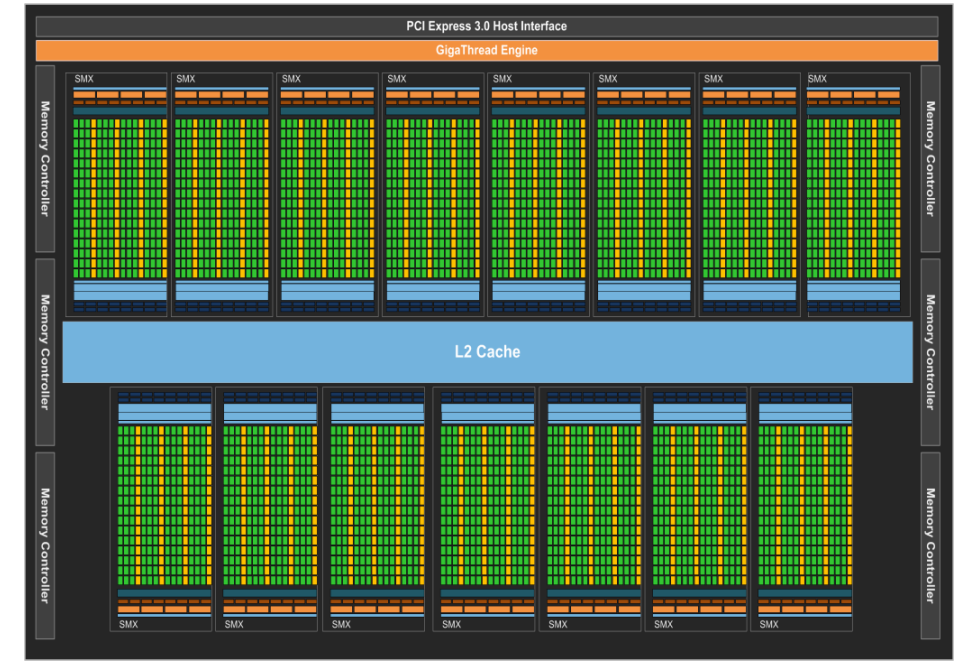
SMX
架构
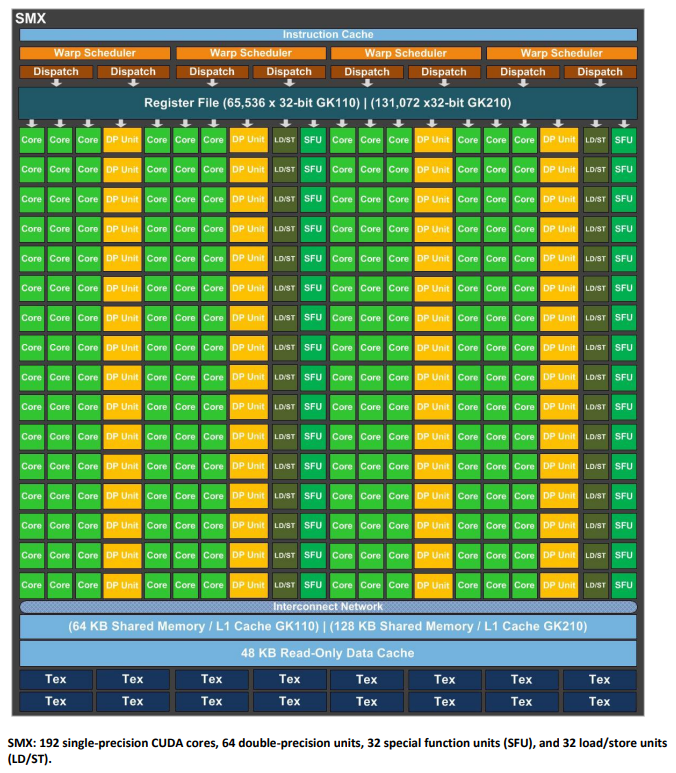
SMX中的core的频率与主GPU频率相同,以增大面积为代价,降低功耗
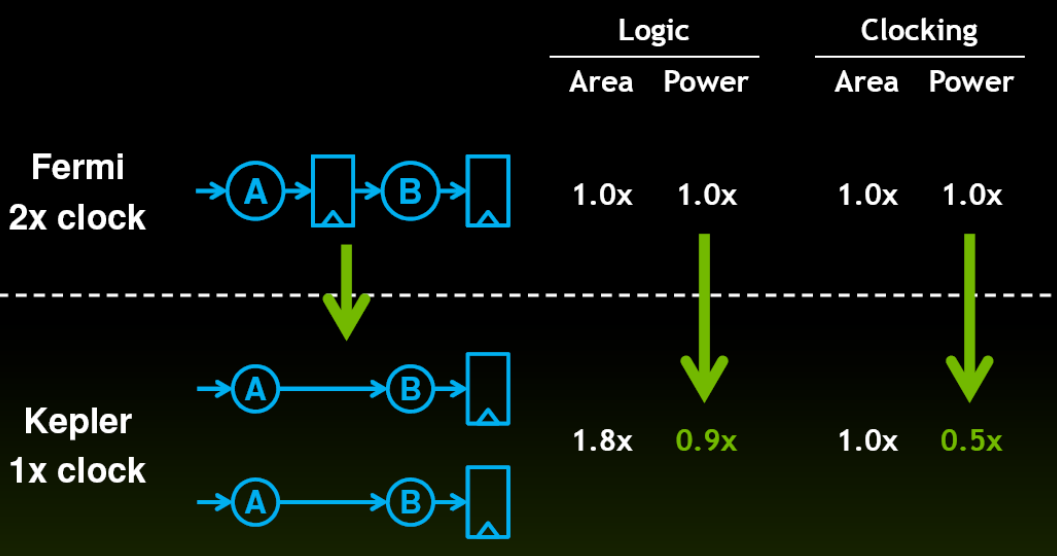
warp scheduler
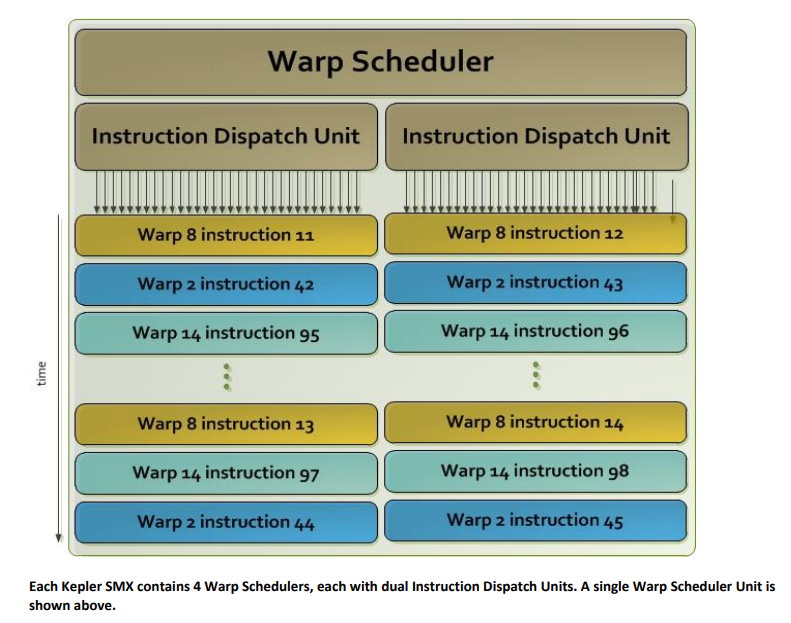
- 4个warp scheduler和8个instruction dispatch unit
- warp scheduler中调度的warp,对应的2个instruction dispatch unit可以在一个周期分配给该warp两个独立的指令
- 两个指令中允许双精度指令与其他指令dual dispatch
- kepler架构针对warp scheduler在降低功耗方面的优化:从硬件的动态调度转向编译器辅助的静态调度
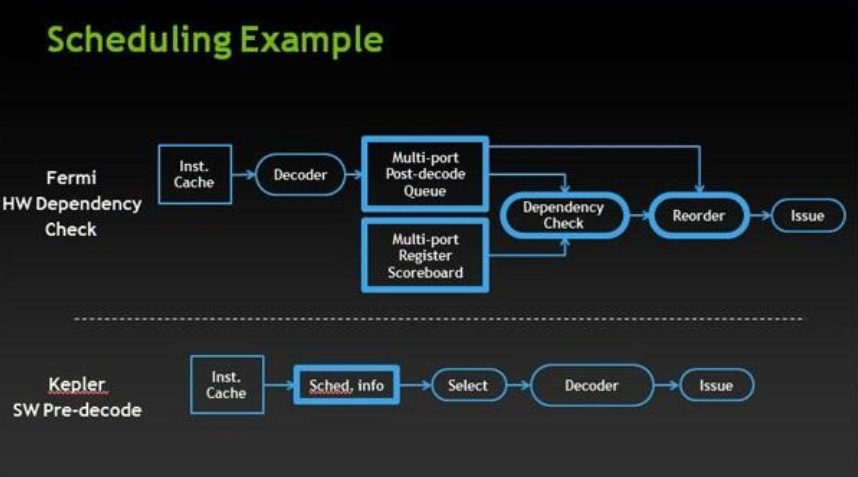
- Fermi用硬件scoreboard来记录寄存器的使用信息,从而确定指令之间的依赖关系
- 硬件scoreboard就是记录各个组件(寄存器、执行单元)当下的情况,并自动根据指令涉及的操作数、ALU去匹配。
- 到了Kepler架构,因为指令的执行周期是可以预计的,所以调度信息其实在编译期就能确定了。于是ISA就做了更改,每7条指令为一组,附加一段调度信息(Control Code),把因为数据依赖需要等待的cycle数记录进去。硬件上许多动态调度的模块被砍掉了,节省了功耗。
- 访存指令的延迟依旧是没法预计的,因为不知道有没有cache miss,所以遇到访存指令势必需要一个等待数据就绪的同步过程,可以借助软件scoreboard来完成。
- 软件scoreboard可以看作是预分配几个信条量,有依赖关系的指令会显式声明对哪几个信号量做操作,这样一来要记录维护的信息变少了,逻辑也简单了。同时软件scoreboard没有dependency check,一方面可以将这部分卸载到编译器,另一方面考虑到dependency不多
- 4个warp scheduler和8个instruction dispatch unit
cache
- Kepler的L1 Cache是用来为reg spill或者stack data服务的,即访存数据其实并不会缓存在L1里。
- 对于那些readonly的global memory,允许借用Tex Cache
shuffle指令:warp可以读取来自warp内其他线程中任意排列的值,因此节省了共享内存
Dynamic Parallelism
Hyper-Q
- 之前架构中只有一个CPU与GPU的工作分配器(CWD)之间的硬件工作队列,多个流复用一个队列,可能造成虚假的依赖性
- 现在有32个硬件工作队列
Grid Management Unit
- 为了支持动态并行,需要改变对grid的管理
NVIDIA GPUDirect
- 可以实现 GPU 与其他设备(例如网络接口卡 (NIC) 和存储设备)之间的直接通信和数据传输,但是中间数据不经过CPU
Maxwell
以GM204为例,4个GPC,每个GPC有4个SMM
特点
- 更高效的SM(Maxwell SM,也称SMM):core数量减少但是效率增加
- 指令调度提升
- 所有核心的SMM功能单元都分配给特定的调度器,没有共享单元。
- 每个分区中的core数量是32,warp scheduler方便调度
- 支持双发射(两个独立的指令,比如一个计算一个访存),也支持单发射(此时正好调度到一个warp)
- 现有代码的占用率增加:每个SM上active的block数量翻倍
- 减少算数指令延迟
- 指令调度提升
- 更大的专用共享内存:
- 每个SMM有64KB的共享内存,4个processing block共享;但是每个线程块只能用48KB
- L1缓存专职服务于texture,L2缓存大小激增
- 快速的共享内存原子操作
- 支持动态并行:Kepler只在高端GPU中支持,Maxwell在低功率芯片中也支持
SMM

Pascal
以GP100为例,6个GPC,每个GPC有5个TPC,每个TPC有2个Pascal SM(但是P100有56个SM)

架构
- SMP

- 每个SM有64个core
- 每个SM中寄存器数量保持不变,因为SM数量更多,所以总的寄存器数量也变多
- 每个SM中共享内存从GM200的96KB下降到64KB,但是因为SM数量更多,因此共享内存总量更大
- 每个SM中有32个双精度FP64 CUDA core
- 支持FP16
- 有专用的共享内存(64KB/SM),L2 cache进一步增大
Unified Memory
Compute preemption
- 计算抢占:允许在GPU上运行的计算任务在指令级别粒度上被中断
- 在Pascal架构之前:
- 仅仅在线程块粒度可以被中断
- 如果GPU上同时运行计算任务和显示任务,则长时间的计算可能会使得显示任务变得不响应和非交互
- Pascal中
- 支持计算抢占,因此显示任务会保持流畅运行
- 同时,计算抢占允许在单个GPU上交互式调试kernel
硬件结构
- 内存从原来的GDDR5更换到HBM
- NVLink:可以GPU之间连接,也可以CPU和GPU之间连接
- 通过NVLink连接的GPU,程序可以直接访问另一个GPU的显存
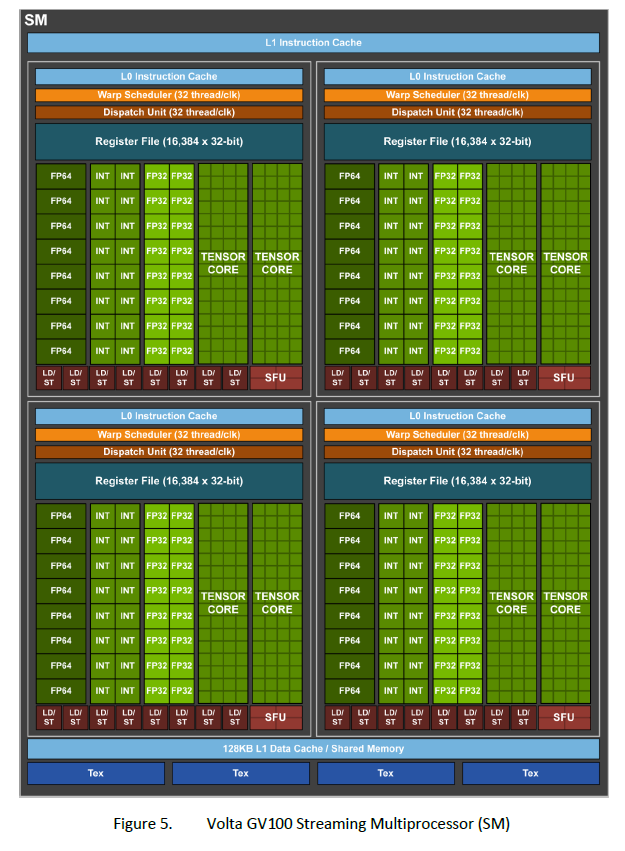
Volta
以V100为例,有6个GPC,每个GPC有7个TPC,每个TPC有2个SM
SM和Tensor Core
core的变化:允许FP32和INT32操作同时执行
- 原来SM是core(ALU+FPU)+DPU的结构,因此FP32与INT32无法同时运行
- 由于ALU都是流水线化、分阶段的,因此虽然ALU和FPU可以同时运行,但是可能处于不同阶段
- 现在SM是FP32+FP64+INT的结构,分离了ALU和FPU
- 因此FP32与INT32可以同时运行
- 而且FP32和INT32可以满吞吐运行
- 对于1个warp共32个线程,交给16个单元去执行的话,要像G80等架构提到的那样占用连续的两个周期来完成issue。不过在第二个周期,dispatch unit可以继续发射指令到其他单元,比如INT32。两者交错起来,就正好能达到满吞吐。
- 虽然增加了1周期的延迟,但是Volta大多数指令延迟都从6个周期降低到4个周期,总体还是快
- 意义:很多程序具有执行指针算术(整数内存地址计算)与浮点计算相结合的内部循环,流水线循环的每次迭代都可以更新地址(INT32指针算术)并为下一次迭代加载数据,同时在FP32中处理当前迭代。
- 原来SM是core(ALU+FPU)+DPU的结构,因此FP32与INT32无法同时运行
Tensor Core
- 每个tensor core在每个时钟周期内,可以执行64个浮点FMA操作(
4*4*4的GEMM) - 每个tensor core执行浮点FMA操作:
D=A*B+C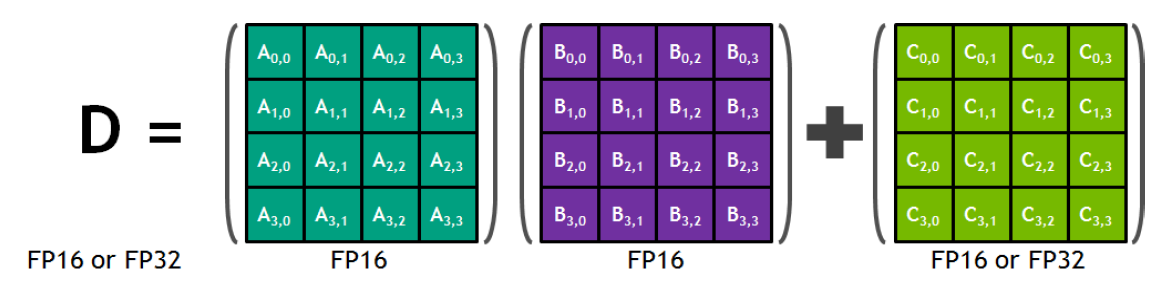
- 每个tensor core在每个时钟周期内,可以执行64个浮点FMA操作(
enhanced L1 data cache and shared memory
- Instruction Cache
- 原来SM中有一个Instruction Cache,每个processing block中有一个Instruction Buffer
- 现在SM中有一个L1 Instruction Cache,每个processing block中有一个L0 Instruction Cache
- 提高了L1 data cache的带宽,降低了其延迟
- 共享内存
- 将共享内存和L1 data cache整合起来,一共128KB,其中共享内存可以分配到96KB
- 纹理内存、全局内存都会经过L1 data cache
- 之前的GPU只有load caching,GV100中引入了write caching
- Instruction Cache
Independent Thread Scheduling
之前的SIMT模型
- 一个warp使用一个共享的程序计数器,作用于32个线程,使用一个活动掩码,masked thread就是inactive的thread。各个分支依次执行,最后reconverge(同步)
- 由于divergence处理成顺序的执行,因此,来自不同区域或不同执行状态的 Warp 中的线程不能相互发送信号或交换数据,同时需要由锁或互斥锁保护的细粒度数据共享的算法很容易导致死锁
- 例子:比如0~3号线程在执行完A之后,需要使用到X的计算结果,此时无法实现
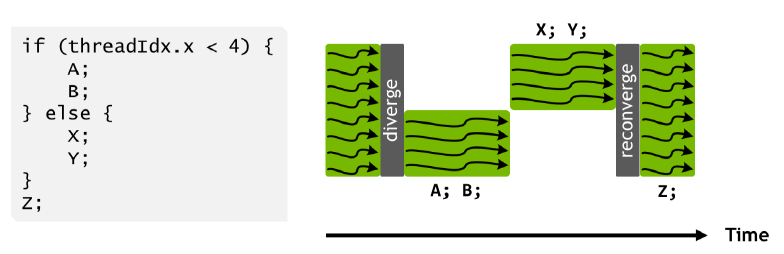
- 例子:比如0~3号线程在执行完A之后,需要使用到X的计算结果,此时无法实现
Volta的SIMT模型:引入独立线程调度,每个线程都有自己的程序计数器和调用堆栈
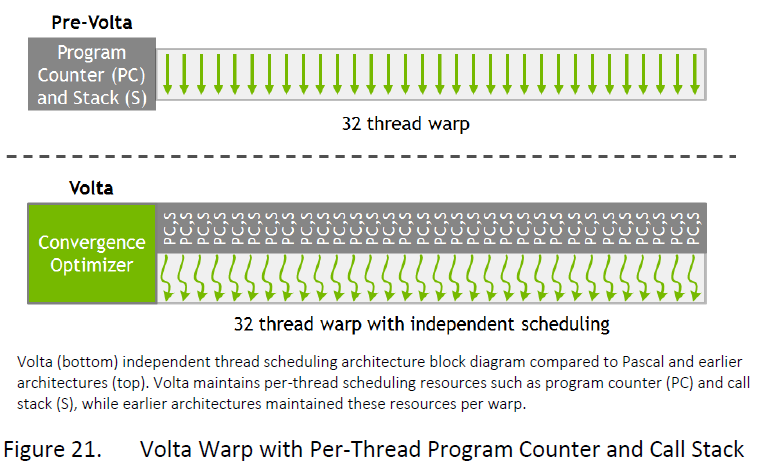
- Volta的独立线程调度允许GPU放弃任何线程的执行,以便更好地利用执行资源或允许一个线程等待另一个线程生成数据,现在线程可以按照子warp粒度进行分支和重新汇聚,同时Volta中的收敛优化器仍会将执行相同代码的线程组合在一起、并行运行以达到最大效率。
- 可以使用CUDA 9的warp同步函数
__syncwarp()来强制warp重新汇聚,因此假设了warp同步的代码不再安全 void __syncwarp(unsigned mask = 0xffffffff)- 二进制位1表示对应的线程参与同步
- 可以使用CUDA 9的warp同步函数
- 虽然一个SM中拆分为了4个processing block,每个processing block16个FP32/INT32,而且每个线程都有自己的PC和stack,看起来half-warp在1个周期内可以直接调度和dispatch到一个processing block;但是每次调度仍然是一个warp(32个线程),消耗2个周期(1个周期调度到1个processing block,2个周期将完整的warp调度完毕)。
- 前面的方法会增加调度硬件的复杂性,而且这种运行时的动态信息会改变各个组件的可用情况,也可能会破坏编译器静态调度的预设状态。
- 例子1:可以实现warp内部细粒度的同步
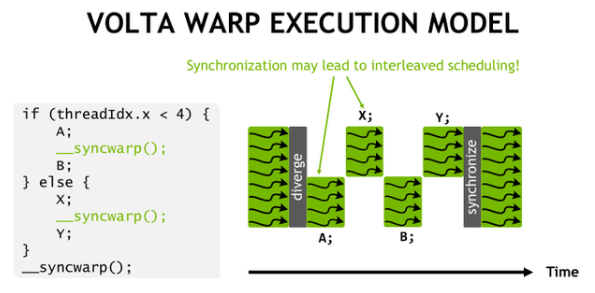
- 例子2:分支间交错执行,可以掩盖stall
- 独立线程调度使得假设了warp同步的代码不再安全,比如此时在执行Z的时候,一个warp中的32个线程没有reconverge(同步),而是保持原来的branch执行
- 这是因为调度程序必须保守地假设Z可能会产生其他分叉执行分支所需的数据,如果是这种情况,自动强制重新汇聚将不安全。
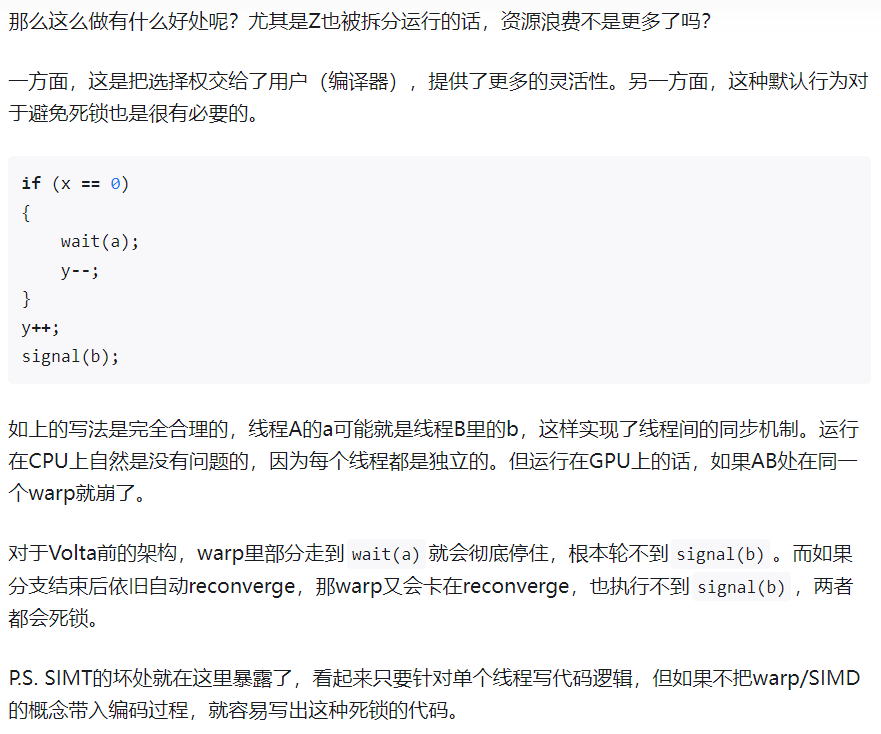
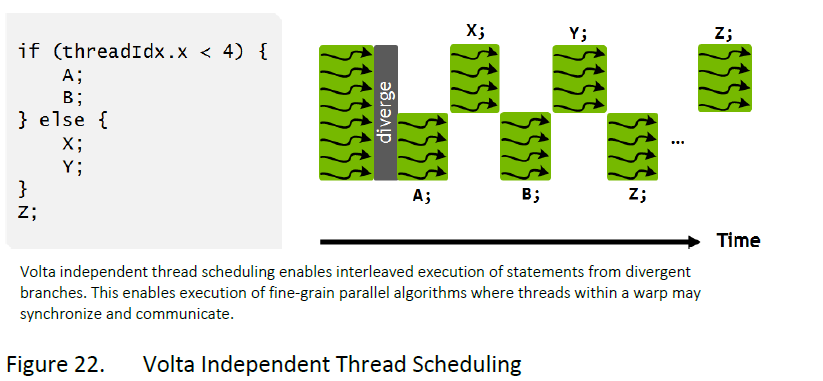
- 这是因为调度程序必须保守地假设Z可能会产生其他分叉执行分支所需的数据,如果是这种情况,自动强制重新汇聚将不安全。
- 此时需要使用
__syncwarp()强制汇聚,可以提高SIMT效率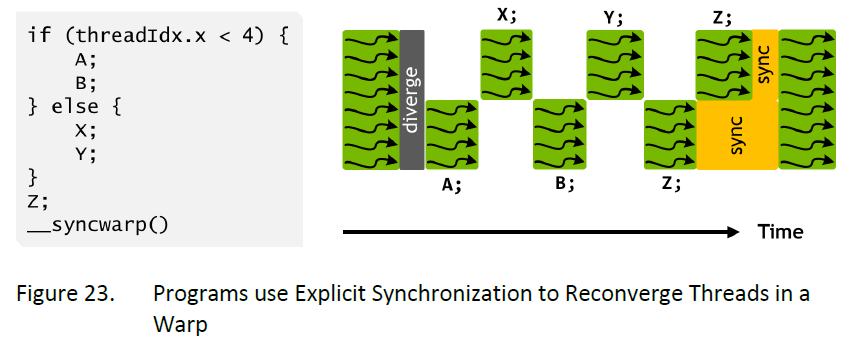
- 因此,从CUDA 9开始,原来的warp shuffle指令
__shfl都变成了deprecated,推荐使用__shfl_sync,里面加入了mask参数
- 独立线程调度使得假设了warp同步的代码不再安全,比如此时在执行Z的时候,一个warp中的32个线程没有reconverge(同步),而是保持原来的branch执行
- 例子3:无饥饿算法,多线程环境下双向链表插入节点
- Volta的独立线程调度确保即使线程T0当前持有节点A的锁,同一warp中的另一个线程T1也可以成功等待锁变得可用,而不会妨碍线程T0的进展。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16__device__ void insert_after(Node *a, Node *b) { Node *c; lock(a); lock(a->next); c = a->next; a->next = b; b->prev = a; b->next = c; c->prev = b; unlock(c); unlock(a); } - 缺点:增加了寄存器负担,单个线程的程序计数器一般要占用两个寄存器
- 参考
- Volta的独立线程调度允许GPU放弃任何线程的执行,以便更好地利用执行资源或允许一个线程等待另一个线程生成数据,现在线程可以按照子warp粒度进行分支和重新汇聚,同时Volta中的收敛优化器仍会将执行相同代码的线程组合在一起、并行运行以达到最大效率。
Multi-Process Service(MPS)
MPS:实现多个计算应用程序共享GPU时的性能提升和隔离
特点
- 保证服务质量:限制每个应用程序只使用GPU资源的一部分,从而降低或消除排队阻塞
- 独立地址空间:不同应用程序进行地址隔离
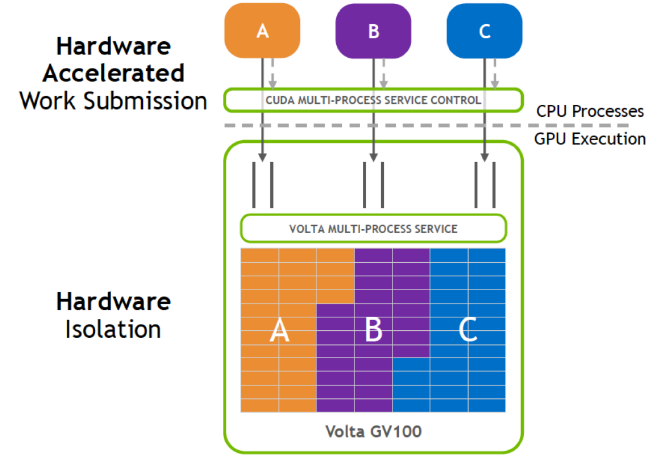
发展
Volta之前都是通过软件方法,使用时间片的方式Time-slice scheduling
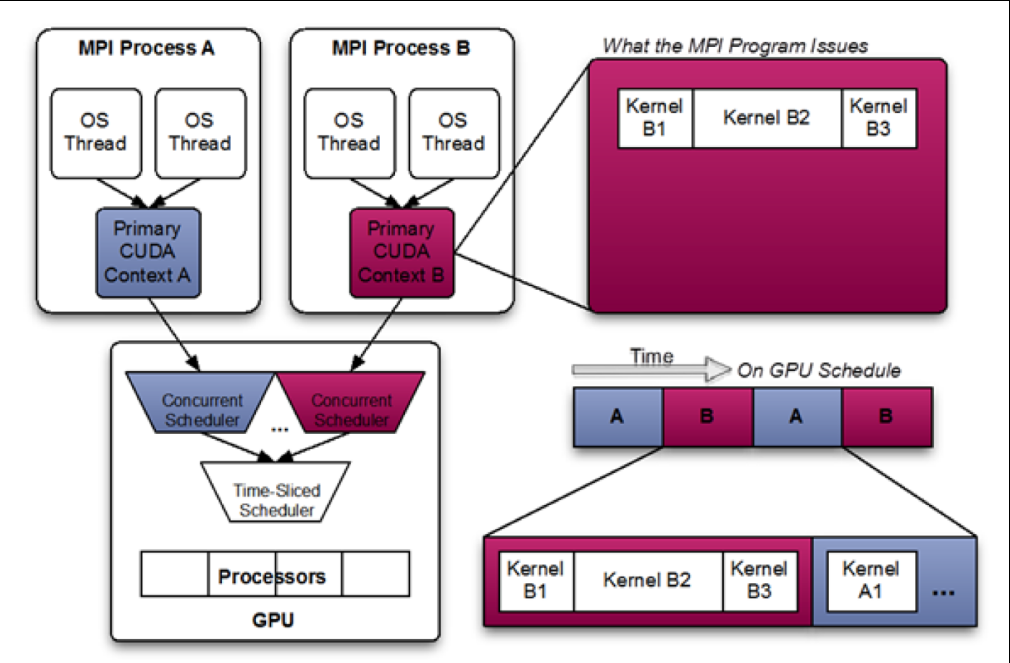
- 从Kepler GK110 GPU开始,NVIDIA引入了基于软件的Multi-Process Service(MPS)和MPS Server,MPS Server允许将多个不同的CPU进程(应用程序上下文)组合成单个应用程序上下文并运行在GPU上,从而实现更高的GPU资源利用率。
- 对于Pascal,CUDA Multi-Process Service是一个CPU进程,它代表已经请求和其他GPU应用程序同时共享执行资源的GPU应用程序。该进程充当中介,将工作提交到GPU内部的工作队列中以进行并发内核执行。
Volta MPS:
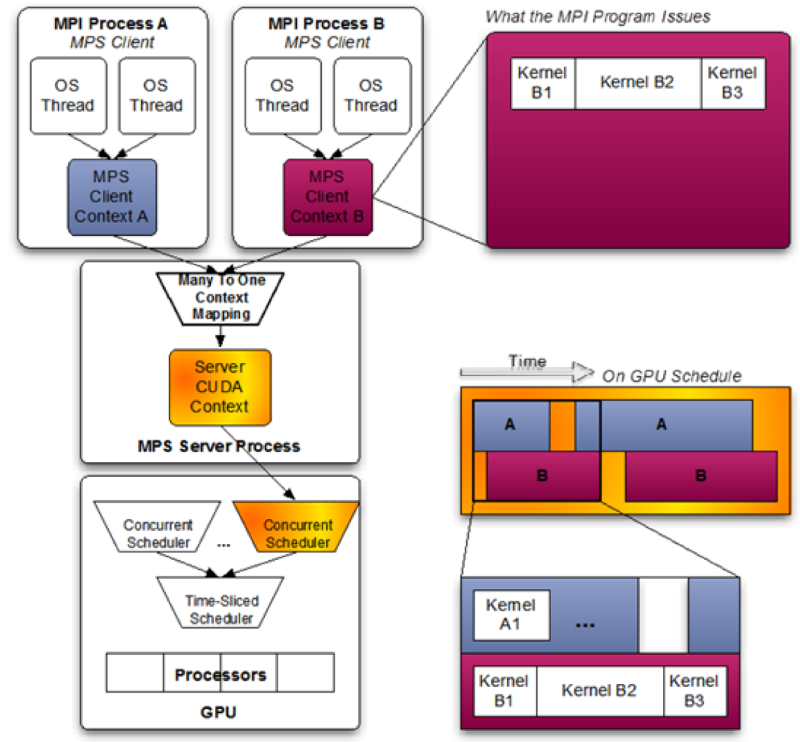
- Server CUDA Context管理GPU硬件资源,多个MPS Clients会将它们的任务通过MPS Server传入GPU
- Volta MPS对MPS server的关键部分使用硬件加速,使得MPS客户端能够直接将工作提交到GPU内部的工作队列中,同时将MPS客户端的最大数量从Pascal上的16增加到Volta上的48
- Volta MPS旨在将GPU共享在单个用户的应用程序之间,并不适用于多用户或多租户用例
- 如果其中一个运行出错,则可能导致运行的任务都失败,即Volta MPS不提供客户端之间的致命故障隔离。
应用:
- No Batching的推理场景中,允许许多单独的单个推理任务同时提交到GPU,提升GPU利用率
- 支持linux下的统一内存,
- 在GPU执行时,之前的MPS client都是运行在一个单独的地址空间,与访问独立CPU进程内存不兼容
Hyper-Q与MPS
- Hyper-Q:多流优化,同一个应用程序下多个stream中,没有依赖的操作可以并行执行
- MPS:同时并行运行多个应用程序,多个应用程序共享同一个GPU context
more reading and reference
Cooperative Groups(CG)
协作组是CUDA 9引入的新特性,允许自定义线程通信的粒度 # CUDA 编程模型之协作组(Cooperative Groups) # CUDA协作组详解
Turing
以TU102为例,有6个GPC,每个GPC有6个TPC,每个TPC有2个SM
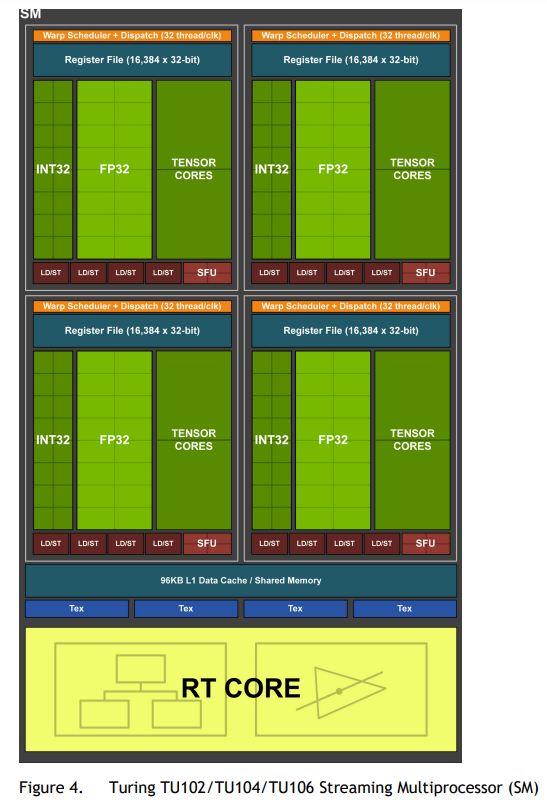
- SM
- 添加了独立的integer datapath,可以与浮点数指令同时运行
- Uniform Register:将共享内存、texture cache、memory load cache(L1 data cache?)重新设计,统一到一起
- 第二代Tensor Core
- 添加了INT8和INT4精度模式,增强了推理性能
- 支持DLSS(Deep Learning Super Sampling)
- 实时光线追踪、渲染管线、RT Core、DLSS等图像相关
Ampere
以GA100为例,有8 GPCs, 8 TPCs/GPC, 2 SMs/TPC
SM
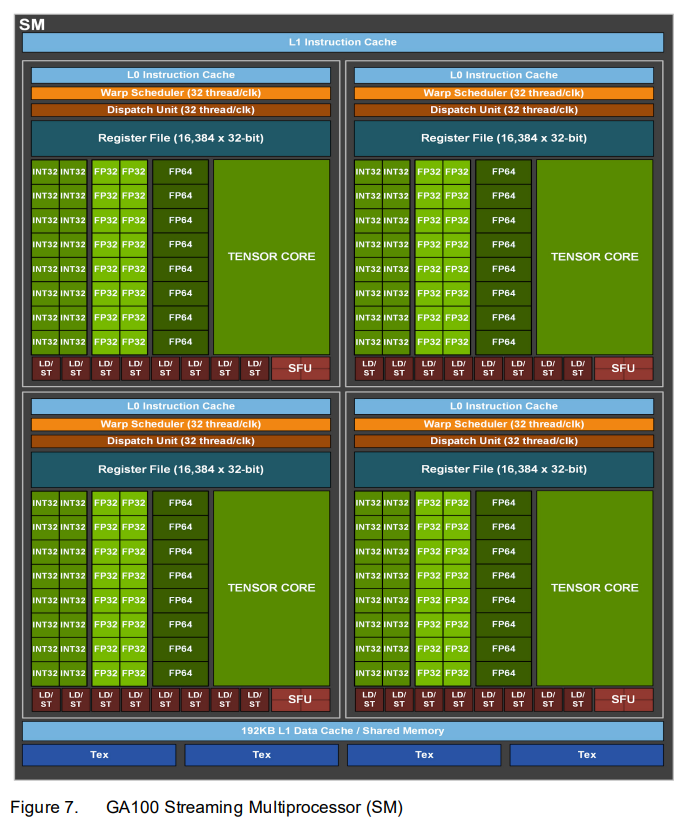
- 第三代Tensor Core
- Tensor Core Sparsity利用2:4的细粒度结构化稀疏性,使得吞吐量翻倍
- 稀疏矩阵定义:2:4稀疏矩阵,即每个四元组中有两个非零值
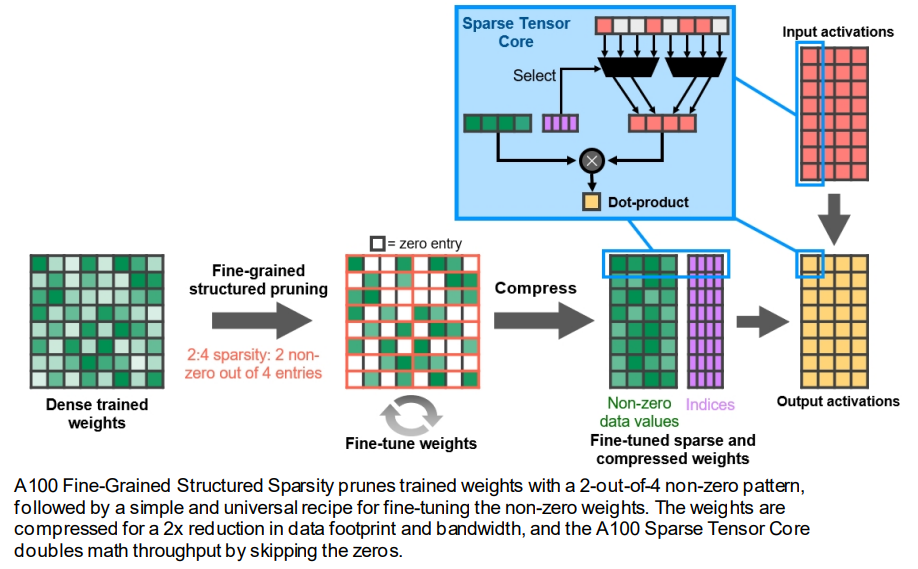
- 过程:使用稠密权重进行训练,然后进行细粒度结构化剪枝,最后通过额外的训练步骤对剩余的非零权重进行微调。
- 具体而言,A100使用Sparse MMA(Matrix Multiply-Accumulate)指令,跳过对带零值的输入进行计算,从而使 Tensor Core 的计算吞吐量翻倍
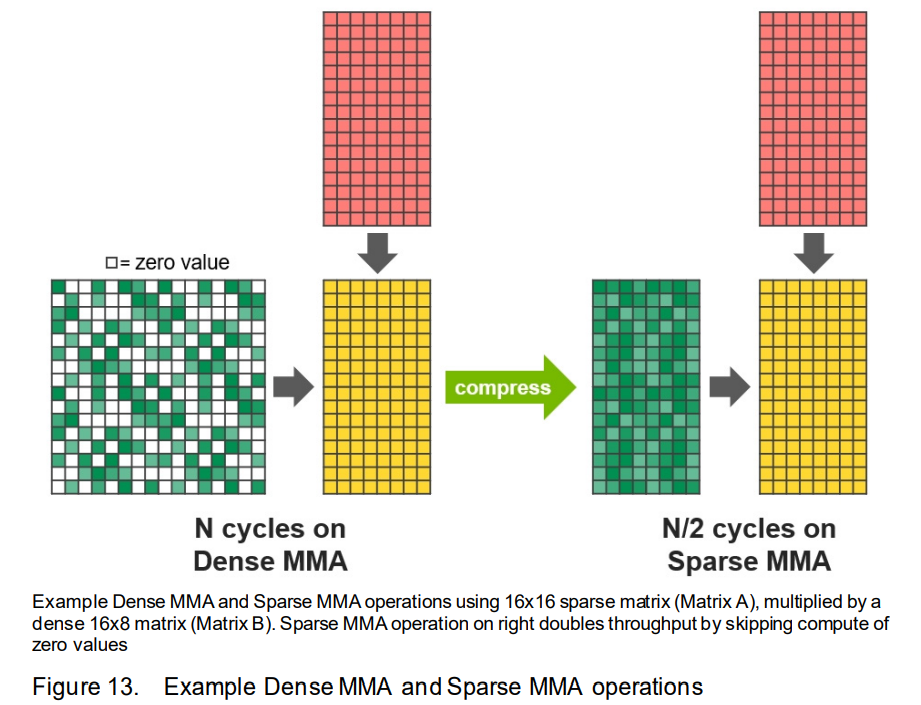
- 稀疏矩阵定义:2:4稀疏矩阵,即每个四元组中有两个非零值
- 支持所有数据类型:FP16、BF16、TF32、FP64、INT8、INT4 和 INT1,且比V100有进一步的加速效果

- 如果不使用Tensor Core,默认使用FP32;如果使用Tensor Core,则默认使用TF32
- 支持FP16/FP32、BF16/FP32混合精度,且两种混合精度速度一样快
- TF32一方面保持了FP16的精度,另一方面保持了FP32的范围,因此很适合训练
- Tensor Core Sparsity利用2:4的细粒度结构化稀疏性,使得吞吐量翻倍
memory方面的改进
Data sharing improvements:
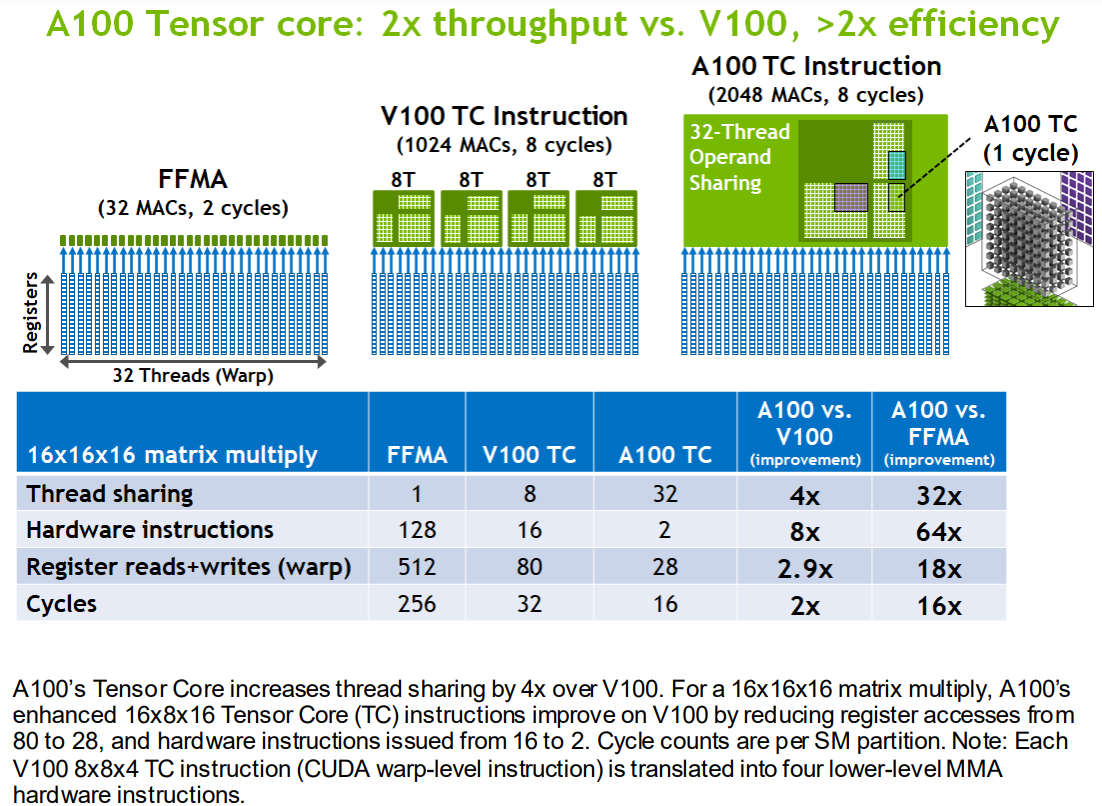
- 数据可以在一个warp中32个线程共享,原来Volta只能在8个线程之间共享
- 因此节省了寄存器和带宽
- 同时,A100 Tensor Core将矩阵乘法指令的k维变为原来的4倍
- 表格中的数据怎么来的?Nvidia tensorCore 计算过程
- 数据可以在一个warp中32个线程共享,原来Volta只能在8个线程之间共享
Data Fetch improvement
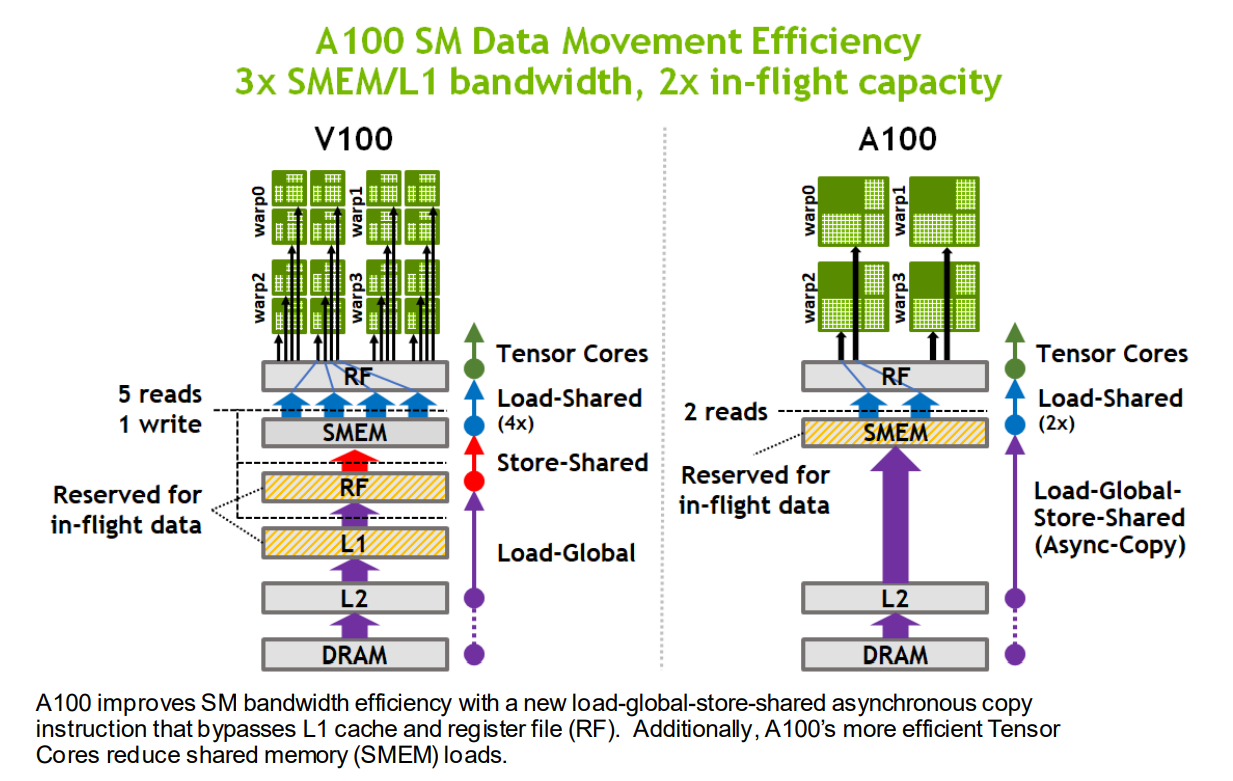
- 新的异步拷贝指令可以直接将数据从全局内存(通常是DRAM和L2缓存)中加载到共享内存中,绕过L1缓存和寄存器
- 原来Volta中,数据先经过L1缓存读取到寄存器,然后再写到共享内存中
- 异步拷贝指令与异步barrier搭配使用:异步拷贝完成后,通过异步barrier通知程序拷贝完成
- Compute Data Compression

- Combined L1 cache and shared memory
- L1 data cache和共享内存整合到一起,一共192KB
- FP32和INT32可以同时运行、且满吞吐运行(与Volta与Turing架构相同)
- Combined L1 cache and shared memory
L2 cache improvement
- 设计改进

- Residency Control:ping-pong buffer(或称double buffer)

- ping-pong buffer常驻于L2缓存上,减少对内存的写回,保持L2中数据重用
- 比如推理场景中,权重分段轮流装载到L2缓存上,让计算与权重装载并行。此时,多batch可以共用更多的权重
- 设计改进
总结

Multi-Instance GPU(MIG)
背景:Volta MPS虽然支持多个应用程序同时运行,但是可能一个应用程序占用太多内存带宽或是L2缓存,对其他应用程序造成影响
MIG
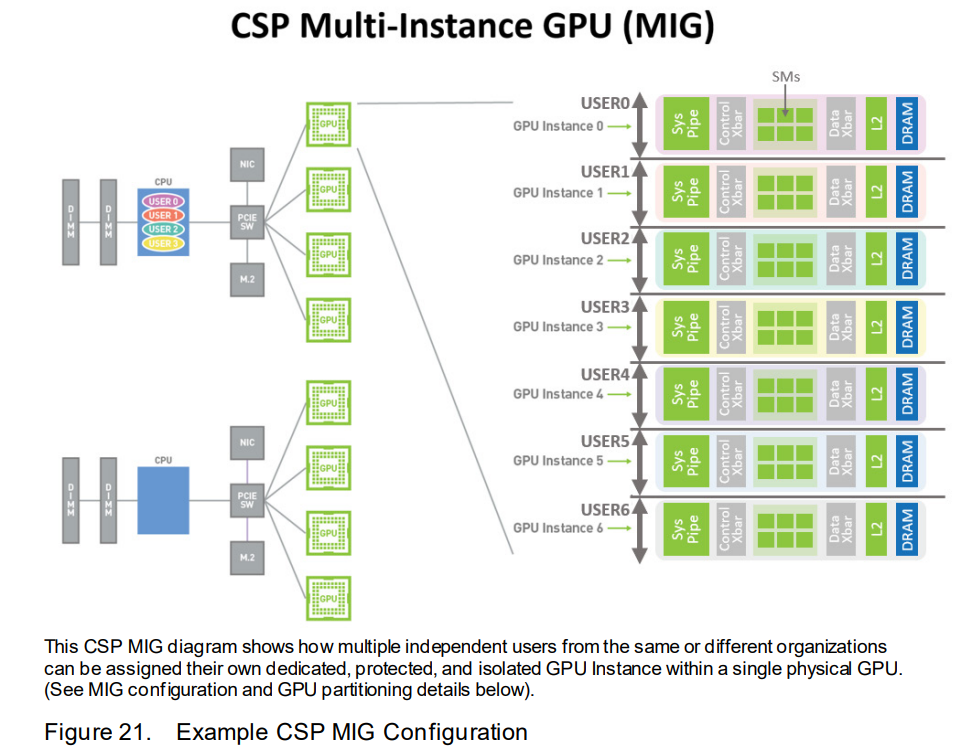
- MIG可以将每个A100 划分为最多7个GPU Instance,每个instance可以为client(虚拟机、容器、进程等)提供定义的服务质量和故障隔离
- 每个instance由若干个GPU slices组成,GPU slices的结构
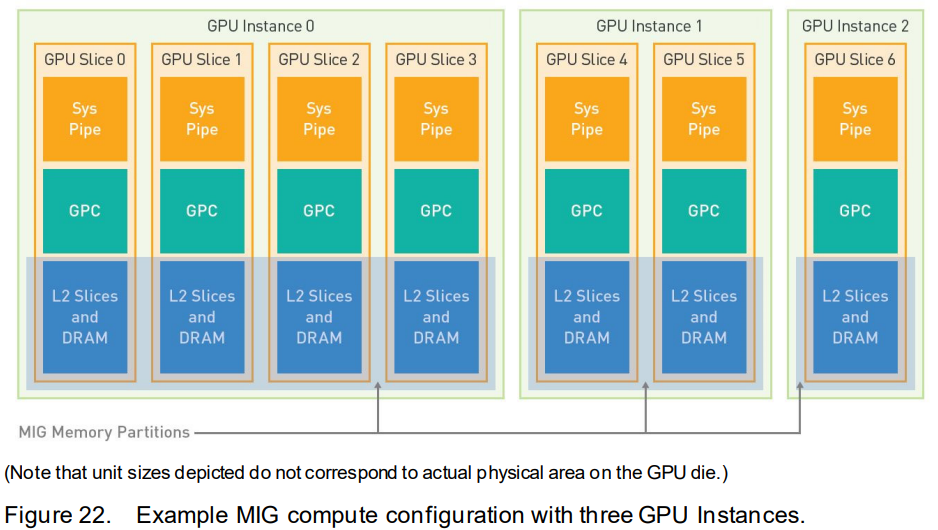
- Sys Pipe:GigaThread Engine的一部分
- 一个GPC(7个TPC,14个SM)
- 一个L2 slice group(包括10个L2 cache slices)
- 对一部分frame buffer memory的访问
- 每个instance内部可以再细分为compute instance
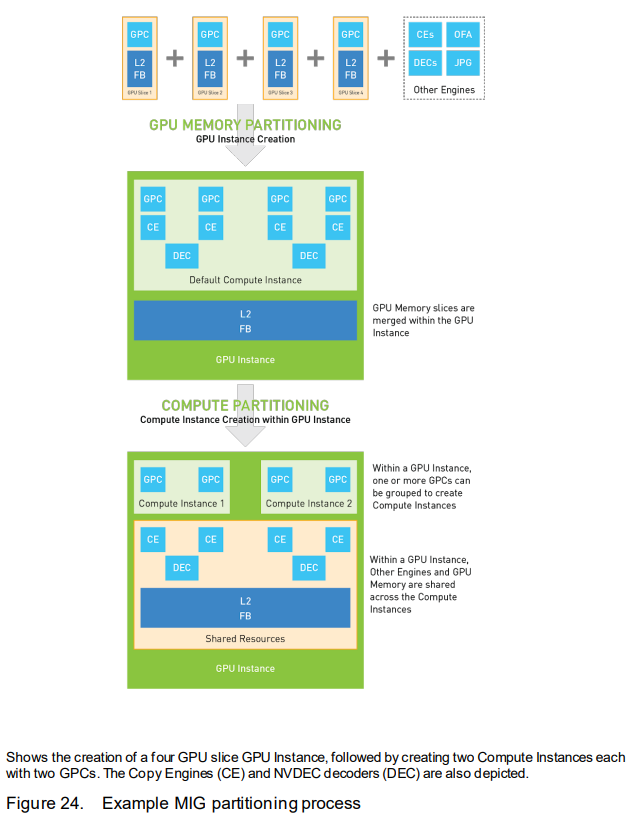
- compute instance可以自行配置和封装计算资源,默认每个instance创建一个compute instance,因此该compute instance使用该instance的全部资源
- 每个compute instance包括一个Sys Pipe和若干个GPC,所有共享一个compute instance的应用程序共享一个Sys Pipe,每个compute instance都可以单独进行上下文切换
- 每个compute instance都支持MPS,MPS client的最大数量与compute instance大小成正比
应用场景:
- Multi-Tenant
- Single Tenant, Single User:一个用户运行多个GPU应用程序
- Single Tenant, Multi-User:比如对外部提供AI服务
CUDA Advances
Task Graph Acceleration
- 背景:对于深度学习等应用场景,有iterative structure(即same workflow is executed repeatedly)
- 以前只能在每个iteration中,CPU重新提交任务到GPU。尤其是很多小的kernel在整个运行过程中,launch、init等开销占了相当一部分时间。
- 现在定义一个task graph(若干个操作、相应依赖关系和一些内存操作),可以define-once/run-repeatedly,即先将多个kernel预先构建为一个task graph,然后CPU一次性launch,减少了launch、init的时间
- kernel的执行流程可以分为三个步骤:launch,grid initialization,kernel execution

- kernel的执行流程可以分为三个步骤:launch,grid initialization,kernel execution
- 加速原理:
- launch optimization:submit multiple work items to the GPU in a single operation
- execution dependency optimization:可以优化复杂的graph(比如workflow fork and re-join,在一个fork分支中可以有多个dependency)
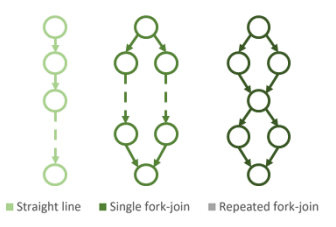
- 背景:对于深度学习等应用场景,有iterative structure(即same workflow is executed repeatedly)
异步数据拷贝和异步barrier:
memcpy_asnyc- 异步数据拷贝:
memcpy_asnyc:从global memory到shared memory的异步数据拷贝cudaMemcpyAsync:从CPU memory到GPU global memory的异步数据拷贝
- 异步barrier:
arrival和wait是分开的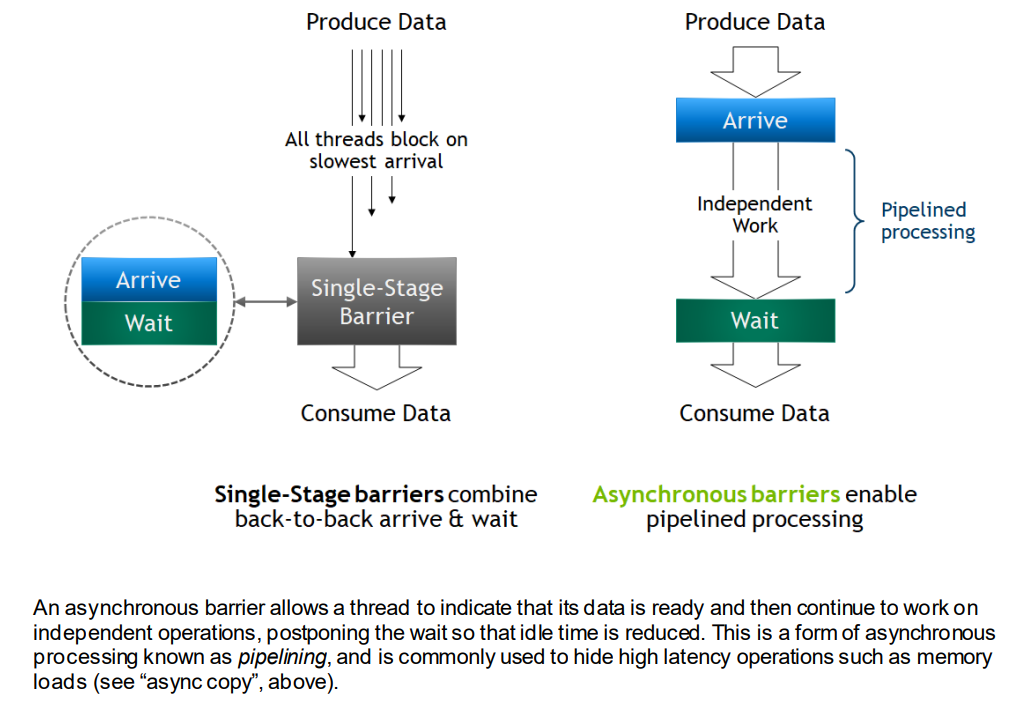
arrival:最快线程到达barrierwait:等待其他线程(或者最慢的线程)到达barrier- 普通的barrier由于各线程快慢不一,中间有idle;异步barrier中间原来idle的部分现在进行其他independent work
- Controlling Data Movement to Boost Performance on the NVIDIA Ampere Architecture:两阶段的pipeline,将计算与拷贝重叠

- 异步数据拷贝:
L2 cache residency control
- 两种数据:
- persisting data:数据重复使用,比如深度学习场景,或生产者-消费者场景
- streaming data:数据只使用一次
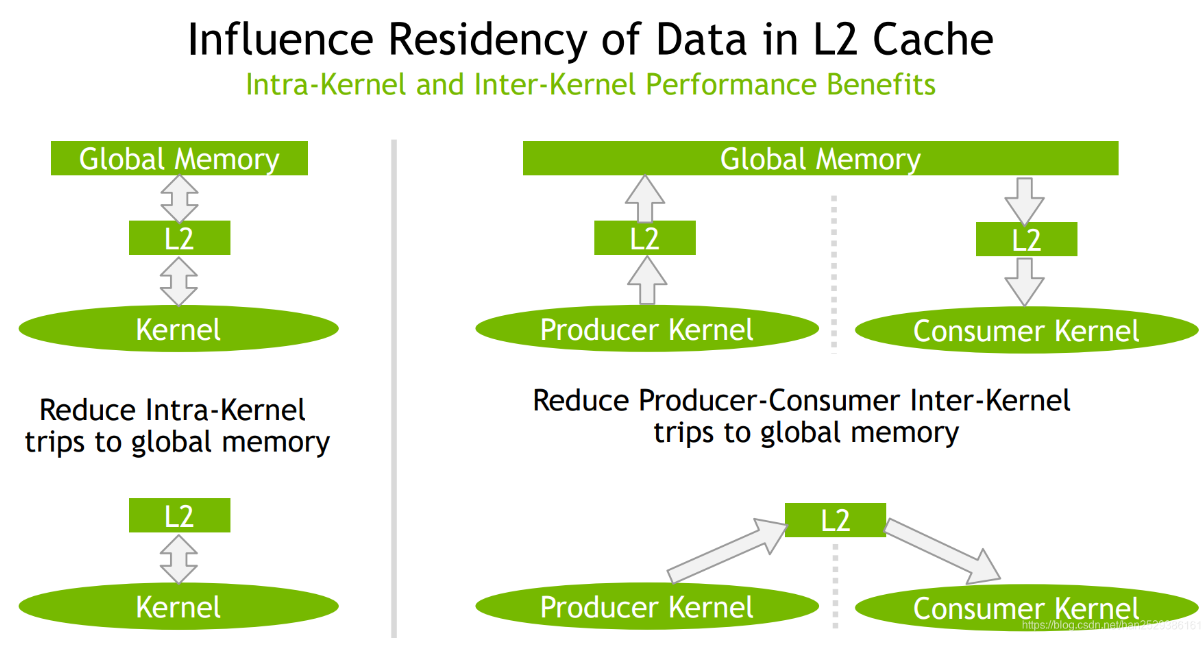
- L2 cache中专门留出一部分给persisting data使用,persistent access优先访问这部分,具体见Device Memory L2 Access Management
- 两种数据:
参考
Ada Lovelace
- cuda core数量增加
- 第四代Tensor Core
- Hopper FP8 Transformer Engine