之前一直对LLM推理过程中的prefill阶段和decode阶段有些困惑,prefill阶段处理prompt,decode阶段自回归地逐token生成。欸,那之前传统机器翻译不也是这样吗,输出一个中文句子,然后再自回归地逐token生成英文句子,有点混乱了。下面我们来重新梳理一下,LLM的发展过程、典型模型架构和训练过程。
开山之作:Attention is all you need
模型架构和训练过程
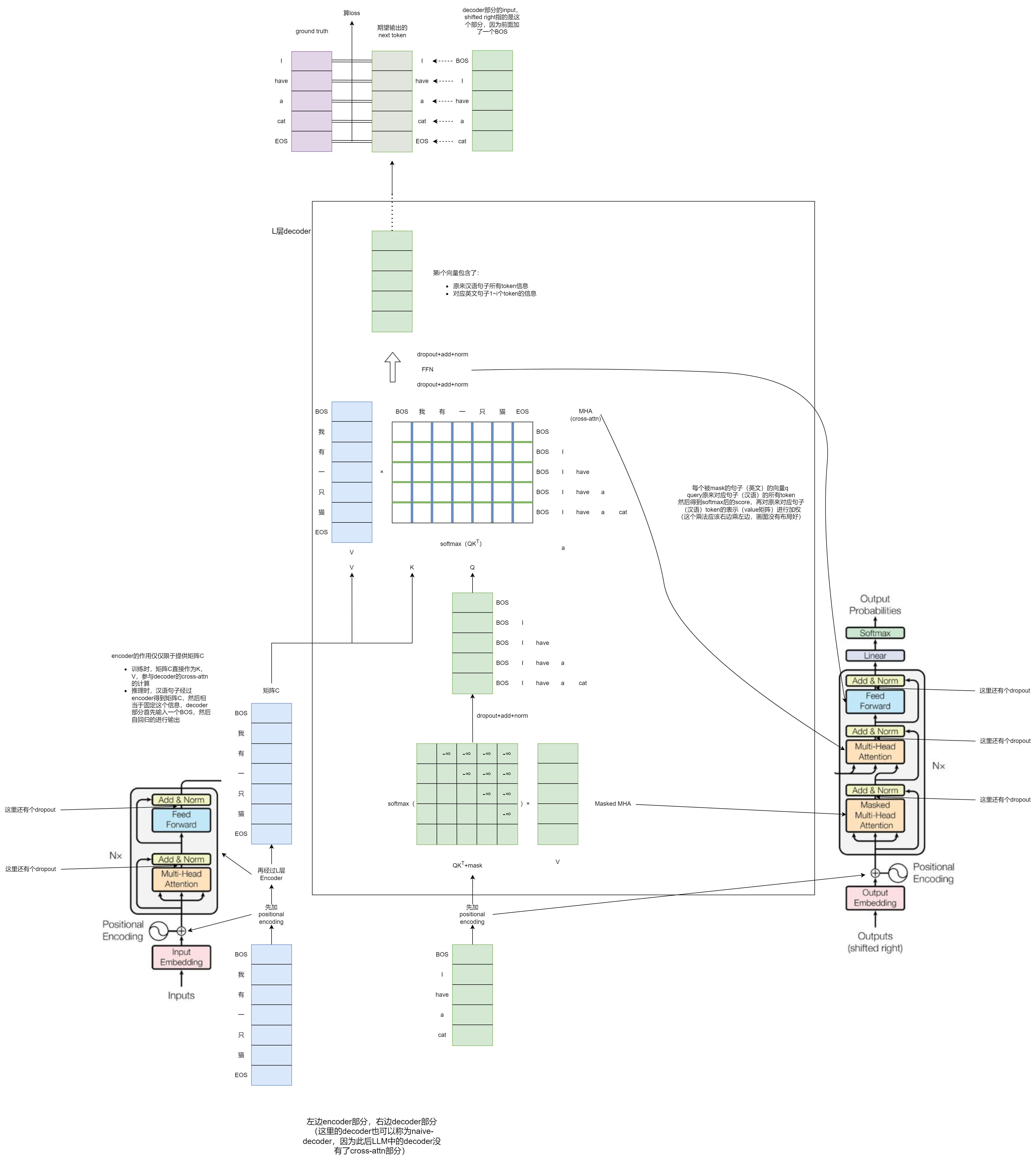
模型架构自不必多说,就像下面最左边和最右边经典的模型架构图所示,是典型的encoder-decoder架构。Transformer一开始,解决的是一个seq2seq的任务(下面以中译英机器翻译任务为例),模型结构中包含了encoder和decoder(将此时的decoder称为naive-decoder),下面图中是encoder-decoder的Transformer的训练过程,左边是encoder部分,右边是decoder部分。在训练阶段,将中文句子经过encoder生成编码矩阵C,将shifted right的ground truth(开头加了BOS的英文句子)作为decoder的输入,整体模型的监督信号是对应的英文句子。因此,训练是并行的,一个iteration就可以将一个中英pair训练完(假设batch size=1),训练任务就是next token predicate。
推理过程
训练完成后,实际使用中开始进行推理。首先encoder部分要输入一个中文句子,还是经过encoder生成编码矩阵C。然后是decoder部分,一开始输入一个BOS,通过自回归的方式逐token生成,渐变的颜色就表示token生成的不同次序。
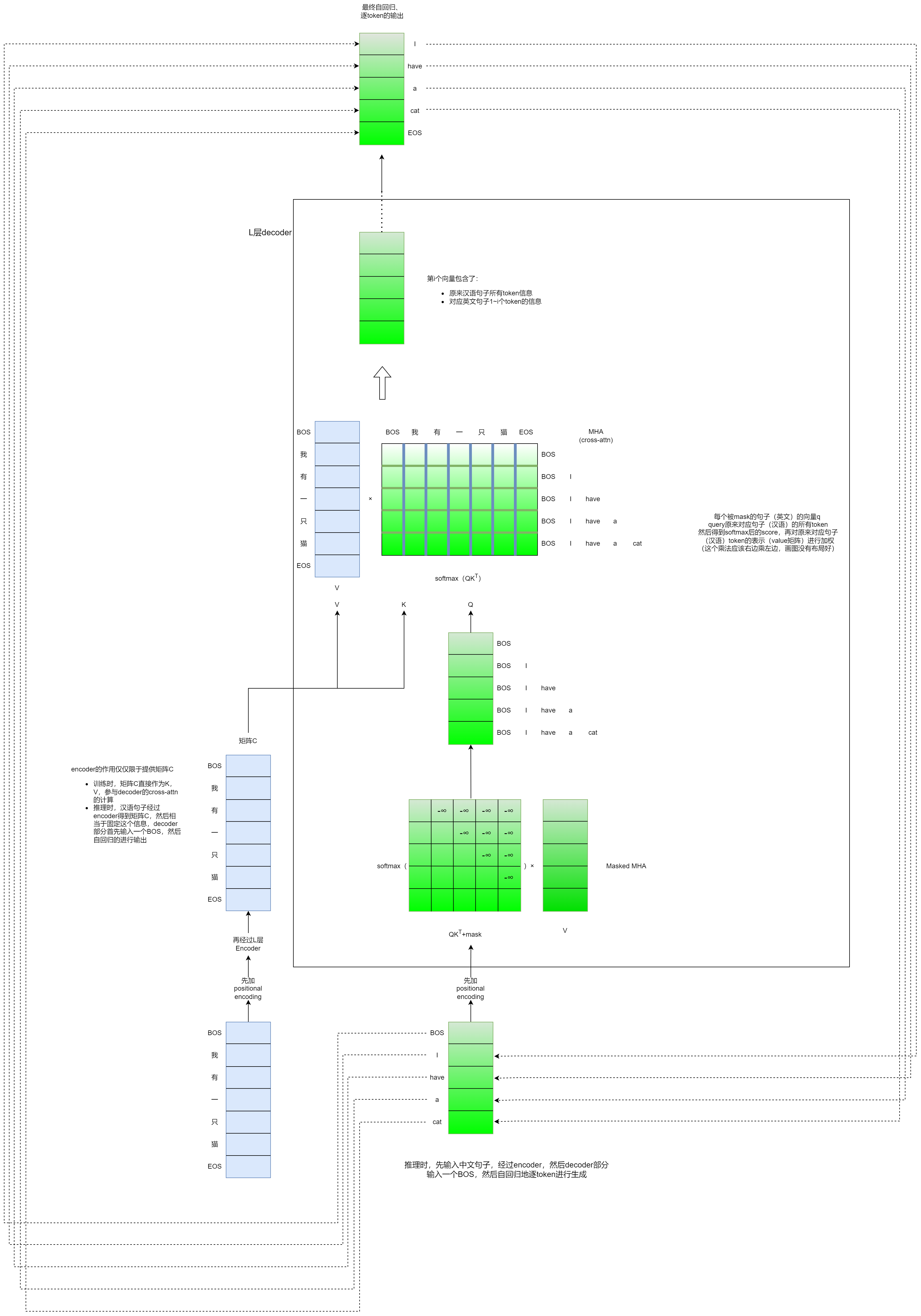
这里有一个问题需要明确一下,每次decoder部分的输入,是一个token呢,还是前面的所有token呢?比如要预测“a”这个token,那么此时decoder的输入是“have”这个token呢,还是BOS+“I”+“have”这三个token都输入呢?其实都可以,
比如每次decoder部分的输入是前面所有的token(比如BOS+“I”+“have”这三个token都输入),那么Masked MHA、MHA部分的Q、K、V都有多行(比如现在是三行),最终decoder出来的这个矩阵,我们只需要最后一个向量(下面红框的这个向量),进行linear+softmax+采样,得到next token

也可以每次decoder部分的输入是一个token(比如预测“a”这个token,只输入“have”这个token),那么此时就需要将之前token的K、V向量缓存下来(即KV-Cache),一个Q向量和concat(当前的KV向量,之前缓存下来的KV向量)算注意力,Masked MHA、MHA部分的attn-score只有一行,然后最终decoder出来的矩阵也只是一个向量,直接进行linear+softmax+采样,得到next token
采用kv-cache的方式,可以在推理过程中减少很多不必要的运算,而且从显存占用来看,kv-cache也是划算的。如果不使用kv-cache,那么每次都要输入之前生成的所有token,Q、K、V都是完整的矩阵;如果使用kv-cache,K、V显存占用与之前相同,Q只是一个行向量而原来只是一个多行的矩阵,使用kv-cache的显存占用相对于不使用kv-cache的峰值显存占用是更少的。虽然说“相对峰值显存更少”,但是需要留意的是,kv-cache还是很占显存的,尤其是大batch_size和长序列的情况下,后面产生了MQA、GQA等优化,这是后话了。
这样看来,似乎在很早以前就有kv-cache的概念,但是似乎在LLM中才真正被普遍应用起来,我想有这么几个原因(not for sure, hope your discussion):
- 之前可能更关注模型架构的改进,之前encoder-decoder架构、encoder-only架构、decoder-only架构没有一个特别突出的模型,直到GPT-3(decoder-only)的出现,掀起了LLM的时代,现在的LLM基本上都是decoder-only的架构
- 在推理场景中,之前的模型上下文长度(或者叫最长序列长度)比较小,计算强度没那么大(但是比如语音流式识别等场景中也会用到kv-cache,不是很确定),LLM时代的transformer上下文长度普遍较大,而且往往是chat场景,对延迟有要求,因此要想法设法减少计算
encoder-only的代表:Bert
Bert是典型的encoder-only架构,其训练和推理过程很相似,训练怎么训,往往推理就是直接一个前向的过程。现在LLM基本都是生成式任务,encoder-only的架构总是感觉很别扭,decoder-only架构就很自然。可以关注知乎问题:为什么现在的LLM都是Decoder only的架构?
LLM时代
模型架构和训练过程
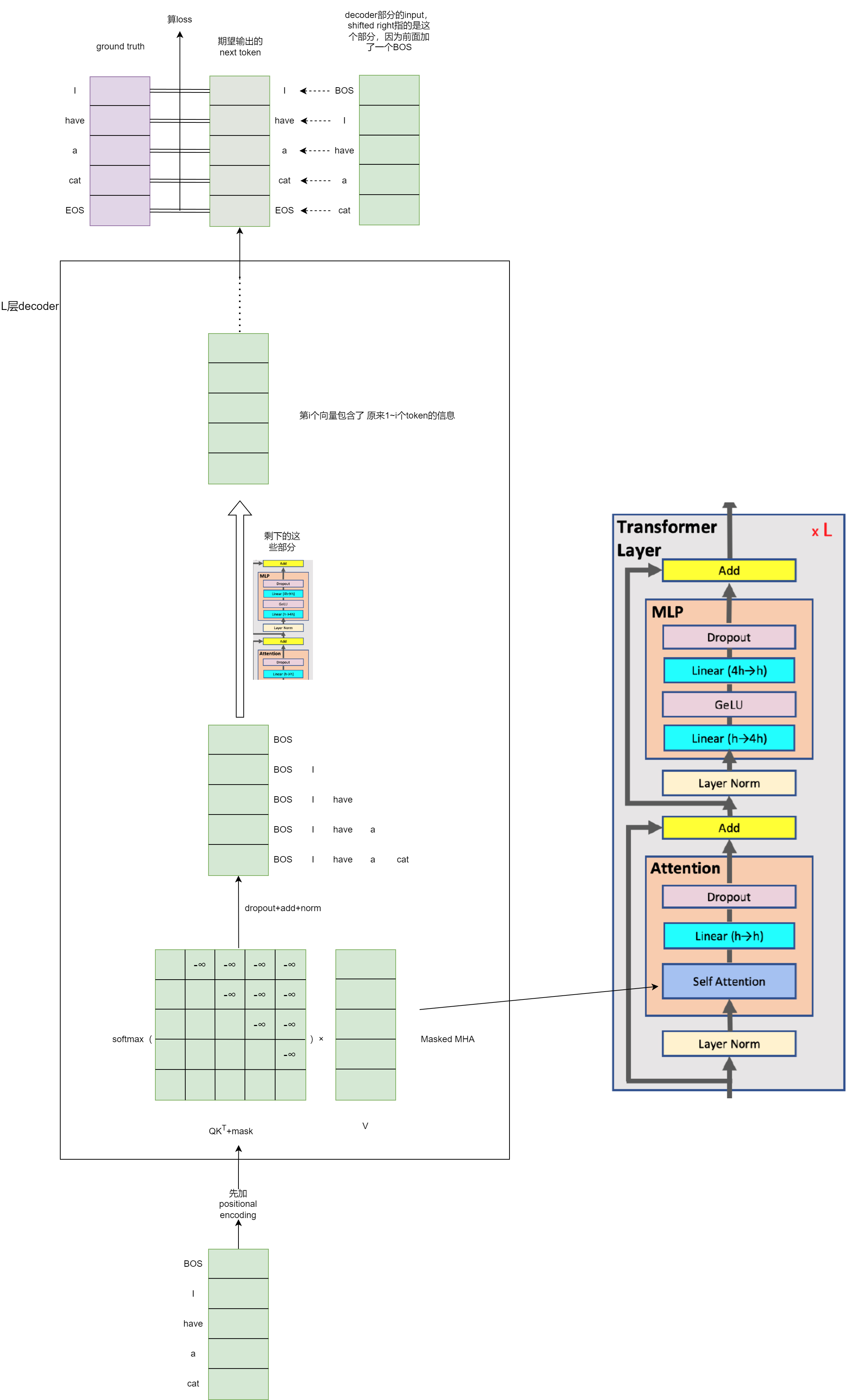
在模型架构方面,GPT-3和Llama只是Decoder-only架构的两个典型代表,基本保持了Vanilla-Transformer-decoder的结构,但是中间很多地方做了改动,比如去掉了与encoder的cross-attn,在masked-MHA的输入QK前面在加上旋转位置编码RoPE,将LayerNomr调整为post-norm结构,MLP部分可能会进行一些调整等,如果仅仅是走一遍训练和推理的流程,那么不会有影响。
从LLM训练过程来看,预训练阶段与之前的语言模型基本一致(如下图,这里不讨论微调、RLHF等过程,更侧重工程和流程方面),都是next token predicate任务,没有了encoder部分,模型结构看起来更加简洁。
推理过程
Decoder-only架构的推理过程和训练过程基本保持了相同的形式,推理过程就是先输入prompt,然后自回归的逐token生成。这里提一下prompt,LLM可以认为是一种特殊的语言模型,语言模型通俗来说就是续写,但是LLM包含了in-context learning的能力,prompt可以认为是一个指令,一个问题,使得“续写”的内容能够反映prompt的意图。
这里我们可以尝试分析一下文章开头提出的疑惑:
- 在encoder-decoder架构的机器翻译任务中,
- 训练过程:中文句子输入到encoder,decoder部分的训练就是语言模型
- 推理过程:中文句子输入到encoder,BOS输入到decoder,然后自回归的逐token进行生成
- 在decoder-only架构的LLM中,
- 预训练过程:没有encoder,就是训练语言模型
- 推理过程:prompt输入到decoder(prefill阶段),然后自回归的逐token进行生成(decode阶段)
LLM推理过程分为prefill阶段和decode阶段,不仅仅是从推理过程上看起来可以分成两个阶段,更重要的是,这两个阶段的特点不同,性质不同,为了尽可能推理加速,才有必要分成两个阶段。
- prefill阶段:输入prompt,生成第一个token。由于prompt往往较长,或者实际使用中将多个prompt打成一个batch(小batch),以提高模型吞吐,所以这个阶段计算量较大。衡量该阶段的一个指标是首字延迟(TTFT,Time To First Token)。还有一个需要注意的是,为了减小decode阶段的计算量,prefill阶段在计算prompt的注意力机制的时候,会将K、V矩阵缓存下来,空间换时间,即kv-cache。
- decode阶段:后续自回归的逐token进行生成的过程,直到生成一个终止符(或者达到长度限制)。该阶段中,每次自回归过程中,输入一个token,然后生成q、k、v向量,k、v向量更新到kv-cache中,然后q向量和矩阵的计算(gemv),计算量较小,访存逐渐称为bottleneck。为了提高计算强度,往往会将多个请求decoder阶段的计算组成一个大batch。衡量该阶段的一个指标是TPOT(Time Per Output Token,生成每个token的耗时)。
上面TTFT和TPOT指标是针对streaming generate场景,如果是non-streaming generate场景,则还是使用经典的延迟(Latency,生成一个完整输出的耗时)、吞吐(Throughput,每秒可以生成几个完整的输出)作为指标。
reference and more reading: